Übersicht
Adaptive Rechensysteme und ihre Entwurfswerkzeuge
Adaptive Rechensysteme haben die Fähigkeit, sich neben der konventionellen Programmierung durch Software auch in Hardware-Aspekten an die Erfordernisse der aktuellen Anwendung anpassen zu lassen. Diese Art von Flexibilität erfordert neue Entwicklungswerkzeuge, mit denen die Soft- und Hardware-Komponenten zur Realisierung eines Algorithmus gemeinsam erstellt werden können. Siehe auch die ausführliche
Allgemeine Einführung.
Die laufenden Arbeiten unseres Fachgebiets Eingebettete Systeme und ihre Anwendungen (ESA) schliessen an umfangreiche Forschungen an der
Abteilung Entwurf integrierter Schaltungen (E.I.S.) der TU Braunschweig an. Seit 1997 kooperierte diese im Rahmen des Projekts
Nimble Compiler for Agile Hardware unter anderem mit der Fa. Synopsys (Advanced Technology Group) und der
Universität Berkeley (BRASS). Als Ziel steht die Entwicklung eines durchgehenden
Entwurfsflusses, der ohne Einschränkungen C in kombinierte HW/SW-Anwendungen übersetzen kann, die dann auf einem geeigneten adaptiven Rechensystem effizient ausgeführt werden können. Während das Nimble-Projekt in 2001 erfolgreich abgeschlossen wurde, gehen unsere eigenen Forschungen auf diesem Gebiet weiter.
Das Nimble-Nachfolgesystem COMRADE wurde in 2004 deutlich weiterentwickelt und kann nun die ersten Beispielanwendungen korrekt in simulierte Hardware übersetzen. Der Fluss wurde durch zusätzliche Optimierungen wie das Aggressive Tail Splitting und eine Bitbreiten-Anpassung der Berechnungen verfeinert. Neben dieser Thematik befasst sich ein laufendes DFG-Projekt, das dem Schwerpunktprogramm 1148 assoziiert durchgeführt wird, auch mit der automatischen Integration von bestehenden Hardware-Blöcken mit den compiler-generierten Datenpfaden.
Mit dem Ziel, nun die Interaktion von Hardware-Architektur und Software-Tools auf Parameter wie Rechenleistung und Leistungsaufnahme zu evaluieren, wird das Projekt an der TU Darmstadt weitergeführt.
Rechnerarchitekturen für adaptive Systeme
 |
| |
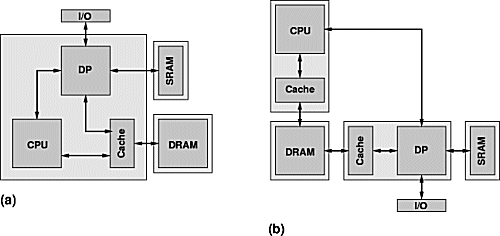
| Bild 1: Hardware-Architekturen |
| (a) Einzel-Chip (ideal, z.B. GARP) (b) Multi-Chip (real, z.B. ACEV) |
Adaptive Rechensysteme (siehe auch
Allgemeine Einführung) können wegen der für sie typischen Flexibilität einzelner Hardware-Teile weitaus besser an aktuelle Erfordernisse angepasst werden als dies mit komplett fester Standard-Hardware möglich wäre. Da aber selbst bei einem adaptiven Rechner der überwiegende Teil des Systems aus nicht-konfigurierbaren Bauteilen besteht, muss auch hier die doch weitgehend statische Rechner-Architektur sorgfältig und ohne die Möglichkeit einer späteren Änderbarkeit entworfen werden. Ein Schwerpunkt unserer Forschung liegt daher auf der Konzeption, Realisierung und Evaluierung verschiedener Hardware-Architekturen für adaptive Rechensysteme.
Beim bisherigen Stand der Arbeiten besteht die ideale Ziel-Hardware (Bild 1) für den Entwurfsfluss aus einem eng gekoppelten rekonfigurierbaren Datenpfad
DP und einem konventionellen Prozessor
CPU, die auf einen gemeinsamen Speicher zugreifen (
DRAM,
Cache). Optional kann der
DP auch noch lokalen Speicher
SRAM und eigene Peripherie
I/O haben.
Der Datenpfad sollte dabei einige Dutzend bis einige hundert ALU-Operationen gleichzeitig realisieren können und ausreichend Flip-Flops für den Aufbau von Pipelines enthalten. Je kürzer die Rekonfigurationszeit, desto effizienter kann der
DP für unterschiedliche Teile der Anwendung wiederverwendet werden.
Da geeignete Bausteine mit den oben genannten Fähigkeiten erst seit kurzem verfügbar sind, wurde in Form der Test-Plattform ACEV an der Abteilung ein adaptiver Rechner aufgebaut, der diskrete Chips für die einzelnen Komponenten verwendet (Bilder 1.b, 2).
 |
| |
| Bild 2: Erprobungs-Plattform ACE1 für adaptive Rechensysteme |
Im einzelnen wird dabei zur Realisierung der Datenpfade ein Baustein Xilinx Virtex XCV1000 verwendet. Ein RISC microSPARC-IIep dient als
CPU. Als Speicher stehen
DP und
CPU gemeinsam 64MB
DRAM zur Verfügung, dem
DP lokal 4 x 1MB ZBT-SRAM. Die Kommunikation zwischen
DP und
CPU erfolgt über einen PCI-Bus. Um die Latenzen der vom
DP ausgehenden
DRAM_-Zugriffe zu minimieren, verwendet auch der _DP einen eigenen
Cache. Die komplette Testplattform steckt als PCI-Karte in einem Wirtsrechner, läuft aber von diesem unabhängig unter einem eigenen Betriebssystem. Dazu wurde das Echtzeitbetriebssystem RTEMS auf die ACEV-Umgebung portiert. Nur für Ein- und Ausgabeoperationen wird nahtlos auf die Peripherie (Dateien, Netzwerk) des Wirtsrechners zugegriffen.
Diese Umgebung erlaubt die praktische Erprobung von Entwurfswerkzeugen, Hardware-Architekturen und konkreten adaptiven Anwendungen auf Systemebene schneller als dies durch Simulationen möglich wäre. Dabei ist allerdings die absolute Rechenleistung bedingt durch den diskreten Aufbau stark beschränkt: Neben der niedrigen Bandbreite und hohen Latenz der PCI-Anbindung ist dafür auch die sehr langsame Rekonfigurationszeit der Virtex-FPGAs verantwortlich. Bei der zukünftigen Verwendung der oben genannten höher integrierten Lösungen (single-chip) mit schneller konfigurierbarer Struktur (ALU statt Logikblock) werden diese Einschränkungen aber aufgehoben.
Die ACE-V Plattform ist mittlerweile ausreichend stabil um auch von einem breiteren Anwenderkreis benutzt zu werden. Um die Fortschritte durch das Verfügbarwerden von höherintegrierten Bausteinen auszunutzen, wurde in 2004 mit der Migration auf die aktuelle Xilinx Virtex II Pro Technologie begonnen. Diese System-FPGAs vereinen bis zu vier RISC-Prozessoren mit zehntausenden von konfigurierbaren Logikblöcken auf einem Chip. Für eine darauf basierende AlphaData ADM-XP Prototypenplattform sind erste Arbeiten zur Erstellung einer passenden Software-Umgebung unter Linux angelaufen.
Entwurf adaptiver Rechensysteme
Die manuelle Entwicklung von Anwendungen für adaptive Rechner ist recht mühsam: Zunächst muss der zu implementierende Algorithmus in Hard- und Software-Teile partitioniert werden. Anschließend werden die einzelnen Teile getrennt realisiert, müssen aber auf beiden Seiten noch mit Schnittstellen und Protokollen für ihre Kommunikation untereinander versehen werden. Die Komplexität der zu lösenden Einzelprobleme bei all diesen voneinander abhängigen Schritten führen zu einer recht niedrigen Entwurfs-Produktivität (siehe auch
Allgemeine Einführung).
Als Alternative dazu wird im Fachgebiet ESA an der Entwicklung automatischer Entwurfsflüsse gearbeitet, die die nötigen Schritte entweder selbstständig durchführen oder den Designer bei seiner Arbeit weitestgehend unterstützen.
Als Ziel steht eine Kette von Werkzeugen, die einen in einer Hochsprache verfassten Algorithmus effizient auf einem adaptiven Rechner implementieren kann. Der erste Prototyp
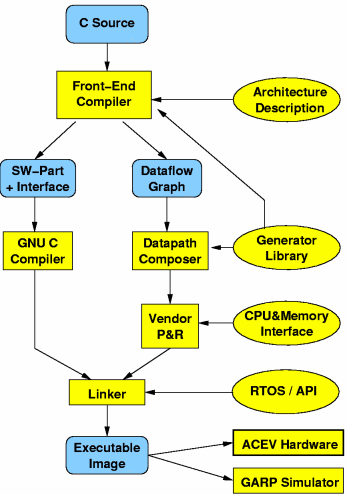
Nimble wurde u.a. in Vorarbeiten an der TU Braunschweig zusammen mit der Fa. Synopsys und der Universität Berkeley entwickelt. Er übersetzt C-Programme in Hardware/Software-Lösungen, welche dann auf einem experimentellen adaptiven Rechner real ausgeführt werden können (siehe auch Rechnerarchitekturen). Den gesamten Nimble-Entwurfsfluss skizziert Bild 3. Im Kern besteht er aus einem ANSI/ISO-kompatiblen C-Compiler und einem datenpfad-orientierten Platzierungswerkzeug.
 |
| |
| Bild 3: Nimble-Entwurfsfluss |
Der als C-Programm vorliegende Algorithmus wird zunächst in Hard- und Software-Komponenten partitioniert. Dabei wird die Auswahl anhand von verschiedenen Arten von Profiling-Daten vorgenommen. Der Software-Teil wird nun nach Anreicherung um Schnittstellen zum parallel entstehenden Hardware-Teil durch den konventionellen GNU-C-Compiler GCC weiterbearbeitet. Die für die Hardware-Ausführung selektierten Teile dagegen werden in Form von Kontroll-Datenflussgraphen zum Scheduling und zur Platzierung an den DatapathComposer übergeben. An dieser Stelle werden auch die Eigenschaften der Ziel-Technologie berücksichtigt. Diese sind durch parametrisierte
Modulgeneratoren abgedeckt, welche für die Basisoperationen des Datenflussgraphen konkrete Schaltungen bereitstellen und sie in Bezug auf Eigenschaften wie Zeitverhalten oder Flächenbedarf charakterisieren können. Abschließend werden beide Teile zu einem auf der Zielplattform (derzeit ACE-V, später auch Virtex-II-Pro-basiert) ausführbaren Programm zusammengebunden (siehe auch
Rechnerarchitekturen).
Flexible Schnittstelle für Modulgeneratoren
Ein Schwerpunkt der Arbeiten im Fachgebiet ESA auf dem Gebiet des
Entwurfsflusses für adaptive Rechner (siehe auch
Allgemeine Einführung) liegt auf der Realisierung effizienter Schnittstellen zu den parametrisierten Modulgeneratoren, die die eigentlichen Hardware-Komponenten erstellen. Dazu wird das bereits früher entwickelte Verfahren
FLexible API for Module-based Environments (FLAME) verwendet. Diese Spezifikation erlaubt den Austausch detaillierter Informationen zwischen dem Hauptentwurfsfluss und den hardware-spezifischen Modulgeneratoren. Der
Compiler kann so beispielsweise Informationen über alle in Hardware realisierbaren Funktionen sowie ihre Ansteuerung abrufen, während der Datenpfad-Platzierer Layout- und Topologiedaten ermitteln kann. Für jeden einzelnen Entwurfsschritt können so die für die Optimierung relevanten Hardware-Charakteristika bestimmt werden.
 |
| |
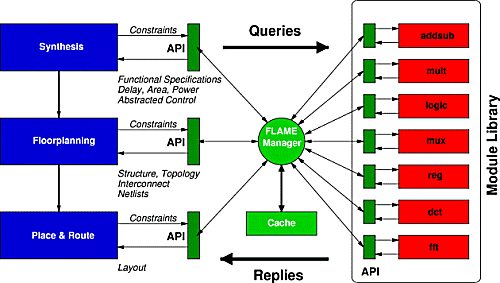
| Bild 4: FLAME-Schnittstelle |
Wie in Bild 4 können bestehende Modulgeneratoren in eine FLAME-Umgebung eingebettet werden. Beliebige Werkzeuge des Entwurfsflusses können so mit dem FLAME-Manager die verschiedenen Dienste der Modulgeneratoren anfordern. Zu diesen Diensten (in FLAME auch
Sichten genannt) gehören beispielsweise neben der Funktion eines Hardware-Moduls auch dessen Schnittstelle nach außen und der Zeit- und Flächenbedarf. Schließlich kann so auch noch die Schaltung selbst als Netzliste abgerufen werden. Diese Einzelschaltungen werden dann von einem übergeordneten Werkzeug zu einem kompletten Datenpfad verbunden.
 |
| |
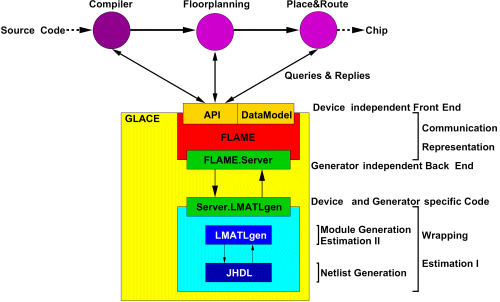
| Bild 5: GLACE |
Bild 5 zeigt das an der Abteilung entwickelte System GLACE (Generic Library for Adaptive Computing Environments), die erste vollständige Modulbibliothek mit FLAME-Schnittstelle. Die in GLACE enthaltenen Modulgeneratoren können die üblicherweise bei der Compilierung von Hochsprachen in Hardware benötigten Operatoren (z.B. Arithmetik, Logik, Multiplexer, etc) flexibel und effizient in Hardware auf Xilinx XC4000 und Virtex FPGAs abbilden. Dem Hauptentwurfsfluss steht via FLAME eine breite Palette von Informationen (u.a. Zeitverhalten, Fläche und Topologie) zur Beurteilung und Auswahl von Modulinstanzen zur Verfügung.
GLACE und FLAME werden kontinuierlich weiterentwickelt. Auch in 2004 wurde die FLAME-Spezifikation weiter gepflegt und erstmals in Form eines Technical Reports vollständig dokumentiert.
Floorplanning-Werkzeuge für datenpfadorientierte Schaltungen auf FPGAs
Nach der Erzeugung von effizienten Modulen für die Einzeloperatoren eines Datenflussgraphen gilt es als nächstes, aus diesen Elementen den kompletten Datenpfad zusammenzusetzen. Bei der Anordnung und Verdrahtung der Einzelschaltungen müssen dabei sowohl die besonderen Eigenschaften der bearbeiteten Datenpfade (Multi-Bit-Operatoren, Pipelining, hierarchische Steuerwerke) als auch die speziellen Eigenschaften der Ziel-Hardware (Carry-Chains, Logikblockarchitektur) berücksichtigt werden.
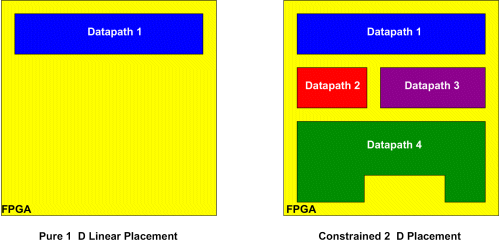 |
| |
| Bild 6: Floorplanning |
2004 wurden erste Arbeiten an einem kombinierten Werkzeug begonnen, dass die Operationen Floorplanning und das Verschmelzen von mehreren Datenpfaden zu einer Konfiguration simultan ausführen kann. Basis für den Prozess sind dabei die Daten, die durch das
Rekonfigurations-Scheduling berechnet werden.
Evaluation repräsentativer Anwendungen auf adaptiven Rechensystemen
Die Eigenschaften von Hardware-Architekturen und Software-Werkzeugen können seriös nur anhand von realen Anwendungen bewertet werden. Zu diesem Zweck wurden in 2004 durch studentische Arbeit eine repräsentative Anwendung vom Algorithmus bis hinunter zur hybriden Hardware-Software-Ausführung realisiert.
Es handelt sich dabei um die Kompression von Graustufenbildern mittels Wavelet-Ansatzes (der ja auch dem JPEG 2000 Standard zugrundeliegt).
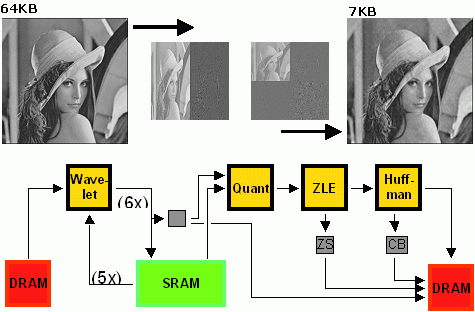 |
| |
| Bild 7: Bildkompression nach dem Wavelet-Ansatz |
Dabei wird das Graustufen-Eingabebild zunächst durch abwechselnde vertikale und horizontale Filterung in niederfrequente (= "wichtige Bildteile") und hochfrequente Teile (= "Bilddetails") zerlegt und diese durch Quantisierung auf einen kleineren Wertebereich abgebildet. Die für das Auge weniger wichtigen Details werden dadurch alle auf den Wert Null gesetzt. Diese langen Ströme von Nullen werden mittels einer spezialisierte Lauflängenkomprimierung in eine einzelne Längenangabe ("15x Null") verkürzt. Eine abschliessende Huffman-Komprimierung ersetzt am Ende des Prozesses noch häufig auftretende Bitfolgen durch kürzere Codes. Eine reale Implementierung dieses Verfahrens auf der ACE-V braucht bei einer Taktfrequenz von 31 MHz 7.2ms zur Bearbeitung eines Bildes. Der Athlon XP Prozessor mit 1533 MHz schafft die Aufgabe zwar in 4.2ms, hat dabei aber eine maximale Leistungsaufnahme von 54-60 W. Selbst ein auf niedrigen Energieverbrauch optimierter Prozessor vom Typ Pentium-M hat eine Leistungsaufnahme von 22 W. Die rekonfigurierbare Recheneinheit auf der ACE-V nimmt dagegen (ermittelt anhand von vollständigen Simulationsdaten) lediglich 0.8 W an Leistung auf. Auch hier gilt das oben Gesagte: Mit einem moderneren FPGA wie dem Virtex II Pro-Chip liesse sich die Rechenleistung bei ähnlicher Leistungsaufnahme mindestens verdreifachen.
Evaluationswerkzeuge für grobgranulare rekonfigurierbare Architekturen
Im Rahmen einer Industriekooperation wurden parametrisierte Platzierungs- und Verdrahtungswerkzeuge erstellt, die anhand einer flexiblen Beschreibungsdatei die Leistungsfähigkeit ganzer Familien von grobgranularen rekonfigurierbaren Feldern erproben können. Mit den so bestimmten Ergebnissen kann dann schon vor der Hardware-Fertigung für jeden Anwendungsbereich die bestgeeignetste Ausprägung der Architektur gewählt werden. Zu den variierbaren Parametern gehören neben der Art und Anzahl der einzelnen Recheneinheiten auf dem Feld auch deren Anordnung und Verdrahtung. Zur Optimierung von Durchsatz und Latenz der Berechnung können verschiedene Arten des Pipelining ebenfalls modelliert werden.
Compiler für adaptive Rechensysteme
Einer der komplexesten Teile eines
Entwurfsflusses für adaptive Rechner (siehe auch
Allgemeine Einführung) ist der zentrale Compiler. Die an einen solchen Compiler gestellten Anforderungen gehen über die von konventionellen Software-Compilern weit hinaus. Neben den gängigen Operationen (Parsing, Code-Erzeugung, Optimierung etc.) muss hier das gegebene Hochsprachen-Programm auch noch optimal in Soft- und Hardware aufgeteilt werden. Weiterhin umfasst der Schritt der Code-Erzeugung sowohl die bekannte Code-Generierung für einen festen Ziel-Prozessor als auch die Generierung optimaler Hardware-Realisierungen für die in Hardware ausgelagerten Teile der Anwendung.
In letzterem Fall könnten für unterschiedliche Anwendungen angepasste Hardware-Architekturen erzeugt werden. Ein Teil des Algorithmus kann also auf einem Vektorprozessor ausgeführt werden, ein weiterer mag besser auf eine superskalare Architektur passen, und ein dritter wiederum könnte ausgeprägte Datenflusseigenschaften haben. Durch die Ausnutzung der Rekonfigurierbarkeit des adaptiven Rechensystems können so für alle Teile optimale Implementierungen gefunden werden.
Da jeder Rekonfigurationsvorgang aber selbst eine bestimmte Zeit benötigt, muss für jede Programmausführung abgewogen werden, an welchen Stellen tatsächlich die Hardware-Konfiguration geändert wird. Andernfalls würde der durch die optimal angepassten Architekturen erreichbare Leistungsgewinn durch zu häufige Rekonfigurationen wieder zunichte gemacht.
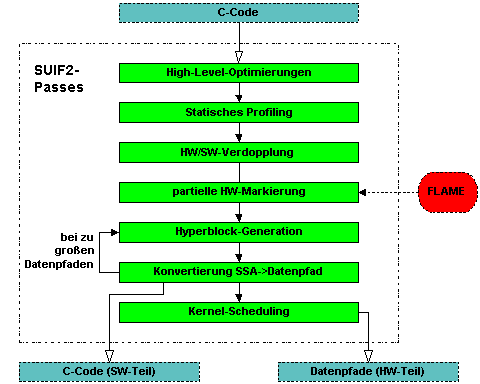 |
| |
| Bild 8: Der Compiler COMRADE |
Das Projekt
COMRADE (Compiler for Adaptive Systems) hat die automatische Umsetzung von C-Programmen in eine Hardware-Software-Partitionierung und die Erzeugung von synthesefähigen Datenpfaden für die rekonfigurierbare Hardware zum Ziel. Aufbauend auf dem Compilersystem
SUIF2 der Universität Stanford erreicht man dieses Ziel durch schrittweise Bearbeitung des Programms (Bild 8).
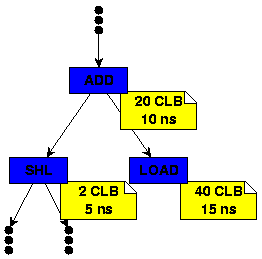 |
| |
| Bild 9: Hardware-Operationen mit technischen Daten |
Welche Teile eines Programms als Hardware oder Software ausgeführt werden, entscheidet der Compiler aufgrund verschiedener Programminformationen. Zum einen sind das hardware-relevante Daten wie Flächenverbrauch und Laufzeit, die von Modulgeneratoren für die Zielhardware über die flexible Schnittstelle
FLAME bereitgestellt werden (Bild 9). Neben den aus dem Modulgenerator-Zugriff gewonnenen Daten ist die Ausführungshäufigkeit von Operationen im Programm für die Hardware-Auswahl wichtig. Die Neukonfiguration der Hardware und die Variablenübergabe zwischen Soft- und Hardware machen seltene Programmteile sehr langsam, da die Kommunikationszeit den Geschwindigskeitsvorteil übertrifft. Deswegen eignen sich vor allem häufig benutzte Schleifen für eine Hardware-Implementierung. Um diese herauszufinden, wird ein dynamisches Profiling eingesetzt. Die Ausführungsfrequenz wird hierbei durch einfaches Ausführen des Programms und Zählen des Ausführens von einzelnen Anweisungen ermittelt.
Die zu einem Programm gehörenden Datenpfade müssen während des Programmlaufs in die rekonfigurierbare Hardware geladen werden. Oft sind sie so klein, dass zugleich mehrere auf ein rekonfigurierbares FPGA-Chip passen. Der Compiler stellt für diese Situation einen Algorithmus bereit, der die von bestimmten Randbedingungen abhängigen Hardware-Rekonfigurationen bestimmt. Das resultierende Scheduling garantiert während des gesamten Programmlaufs eine gute Ausnutzung der Hardware-Ressourcen.
Zwischendarstellung für Hardware-Auswahl und Datenpfad-Synthese
Eine besondere Bedeutung in COMRADE nimmt die Zwischendarstellung ein, für die eine Sonderform der Static-Single-Assignment-Form (SSA-Form) von Kontrollflussgraphen gewählt wurde. Diese unterstützt einen Großteil der Umformungen, welche auf dem Hardware-Teil eines Programms vorgenommen werden müssen. Außerdem vereinfacht sie die Umsetzung dieser Regionen in die Hardware-Datenpfade.
Die grundlegende Eigenschaft einer SSA-Form besteht darin, dass in ihr jede Variable nur einmal definiert wird. Da normale Programme diese Eigenschaft im allgemeinen nicht besitzen, müssen sie zuerst in die SSA-Form konvertiert werden (Bild 12).
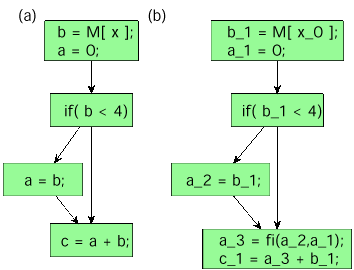 |
| |
| Bild 10: Konvertierung in SSA-Form |
Man erkennt, dass an Stellen, an denen sich die Definitionen von mehreren Variablen vereinigen müssen, sogenannte Fi-Anweisungen eingefügt werden. Diese Anweisungen werden in einem späteren Compiler-Schritt dann in Multiplexer umgeformt. Auf diese Weise können verschiedene Lösungen für eine Variable parallel berechnet werden. Der erzeugte Multiplexer sucht dann aufgrund von Kontrollfluss-Informationen das richtige Ergebnis heraus. Alle anderen Berechnungen werden beendet oder verworfen.
Die in COMRADE verwendete Data-Flow-Controlled SSA-Form (DFCSSA-Form) erweitert die Eigenschaften der einfachen Form durch Elemente, die für das Erstellen von Datenpfaden und deren Scheduling vorteilhaft sind. Als erstes wird die Zwischendarstellung nur für als Hardware vorgesehene Teile des Programms erzeugt. Eine Zeitersparnis während der Compilierung ist die Folge. Desweiteren werden in der DFCSSA-Form Fi-Anweisungen nur an die Stellen gesetzt, an denen sie wirklich nötig sind. Dadurch können Multiplexer entstehen, welche mehr als zwei Eingänge besitzen. Diese erzielen Laufzeitvorteile auf der Ziel-Hardware.
Interaktion mit dem Modulgenerator GLACE
Die Entscheidung über die Auswahl einer Operation als Hardware- oder Software-Implementierung beruht teilweise auf aus Modulgeneratoren erzeugten Informationen. Wir benutzen den Modulgenerator GLACE, um Größe und Laufzeit von Blöcken auf der rekonfigurierbaren Logik abzuschätzen. Dabei müsste für jeden Operator eine neue Anfrage an den Generator gestellt werden. Viele im C-Sourcecode enthaltenen Operationen ähneln sich aber, und Anfragen würden so ohne einen geeigneten Mechanismus mehrfach gestellt. Desweiteren werden zur Zeit noch alle Anfragen über das Java Native Interface (JNI) an GLACE geleitet, da COMRADE in C++ und GLACE in Java implementiert sind. Der Zugriff wird dadurch verlangsamt. Aus diesen Gründen verfügt COMRADE über einen internen Cache, der Anfragen an GLACE zwischenspeichert und somit die Bearbeitungsgeschwindigkeit beschleunigt (Bild 11).
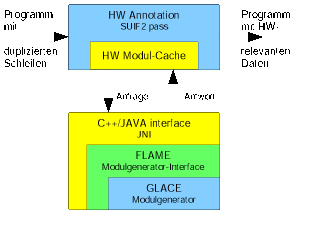 |
| |
| Bild 11: Cache für den Zugriff auf GLACE |
Messungen an Benchmarks haben gezeigt, dass mindestens 77% aller Anfragen an den Modulgenerator durch den Cache eingespart werden können.
Modulgeneratoren können für viele der in C vorhandenen Operationen Module erzeugen. Leider sind Fähigkeiten aber beschränkt, so dass der Compiler selbst Synthese-Aufgaben übernehmen muss. So erzeugt COMRADE beispielsweise Multiplexer mit mehr als zwei Eingängen selbst, da diese von GLACE zur Zeit noch nicht unterstützt werden. Desweiteren können auch Optimierungsaufgaben übernommen werden. Logische Operatoren (
&&,
||) und bitweise Operatoren (
&,
|,
^) der Programmiersprache C werden von GLACE nur unter Angabe von Wahrheitstabellen unterstützt. Diese auf den ersten Blick hinderliche Eigenschaft gibt uns wiederum die Möglichkeit, jede beliebige logische Funktion zu realisieren. Wir nutzen dies, um Kombinationen von Operatoren wie z.B.
d = a | b | c & a zu einem Operator zusammenzufassen. In Bild 12a wird beispielsweise die Anweisung
y = (((a & b) | ((c & d) & e)) | (((e & f) & g) & h)
unoptimiert dargestellt.
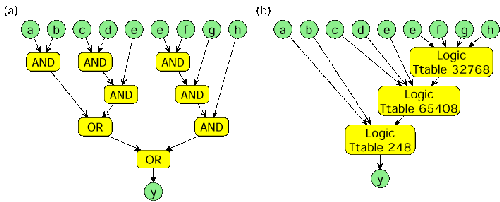 |
| |
| Bild 12: Optimierungen logischer Operationen |
Im Gegensatz wurde die Darstellung in Bild 12b durch die Synthese-Bibliothek SIS soweit optimiert, dass nur noch drei Operationen verwendet werden müssen. Hier werden dann auch alle in der Ziel-Hardware vorhandenen vier Eingänge pro Logikblock (CLB) benutzt.
Compiler-Optimierungen für adaptive Rechensysteme
Neben klassischen Methoden wie der Optimierung von Speicherzugriffen und kontrollflussbasiertem Profiling werden speziell auf die Ziel-Architektur angepasste Verfahren benutzt, um vorrangig die Rechenzeit zu vermindern. Besonders das Pipelining sorgt für hohe Parallelität in den erzeugten Datenpfaden. Der Compiler erkennt automatisch Ansatzpunkte für Parallelität im Programm und baut diese ohne den Eingriff eines Designers in die Datenpfade ein.
Die meiste Zeit eines Programms wird in Schleifen verbracht. Als gute Faustregel gilt, dass 90% der Zeit in 10% des Programms verbracht werden. Es liegt also auf der Hand, dass eine Verbesserung dieser 10% am lohnendsten ist. Da sich jedoch die Eigenschaften von adaptiven Computersystemen deutlich von denen von Standard-Hardware unterscheidet, sind die bekannten Optimierungen nicht im gleichen Maße wirksam. Es muss evaluiert werden, welche Vorteile bekannte Verfahren bringen. Ebenso sind auch neue Optimierungen zu untersuchen.
Schon am eingelesenen C-Sourcecode kann der Compiler Optimierungen vornehmen, die sich direkt in der erzeugten Hardware auswirken. Der eingelesene C-Code wird intern als Baum dargestellt. Dabei entstehen auch Teilbäume, welche bei einer Umwandlung in einen Datenflusgraphen keine minimalen Laufzeiten haben. Wird z.B. die Anweisung
e = a + b + c + d eingelesen, so wird ein Baum der Höhe 3 (Bild 13a) erzeugt. Die Laufzeit dieses Baums könnte aber durch eine andere Klammerung
(e = (a + b) + (c + d)) um 33% verkürzt werden. Eine perfekte Baumhöhenreduzierung ist aber nur mit NP-vollständigem Aufwand durchführbar. In COMRADE wird dagegen eine Heuristik benutzt, welche Assoziativität und Kommutativität von Operatoren ausnutzt, um durch lokales Verdrehen von Operatoren oder Operanden schon in der Zwischendarstellung eine Laufzeitreduzierung in der endgültigen Hardware herbeizurufen (Bild 13b).
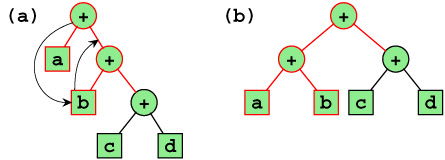 |
| |
| Bild 13: Baumhöhenreduktion durch Operator-Verdrehen |
Diese erzeugt zwar nicht in jedem Fall eine optimale Lösung. Doch wird vor allem bei sehr hohen Bäumen eine Reduzierung der Zeit für das Compilieren erreicht.
Als sehr gewinnbringend für die Größe von Hardware hat sich die Reduzierung der Bitbreite von Operatoren erwiesen (Bild 14). Dabei werden in Ausdrucksbäumen Informationen von Konstanten mit den Eigenschaften von bitweisen (AND, OR) und mathematischen (+, -) Operatoren verknüpft und so nicht benötigte Bits identifiziert. Dabei können auch Operatoren vereinfacht oder durch Verdrahtung ersetzt werden. Eine Multiplikation mit Zwei lässt sich beispielsweise durch ein einfaches Schieben ersetzen. Neben der Einsparung von Ressourcen sind Operatoren mit einer kleineren Breite meist auch schneller.
 |
| |
| Bild 14: Bitbreitenreduktion zur Einsparung von Ressourcen |
Verbesserungsmöglichkeiten der Bitbreitenreduktion ergeben sich, wenn vorher eine als Constant-Propagation bezeichnete Optimierung ausgeführt wird. Dabei werden alle als konstant erkannten Variablen eines Programms durch die Konstanten selbst ersetzt. Diese werden dann von der Bitbreitenreduktion in die Optimierung eingebunden.
Hardware-Software-Partitionierung
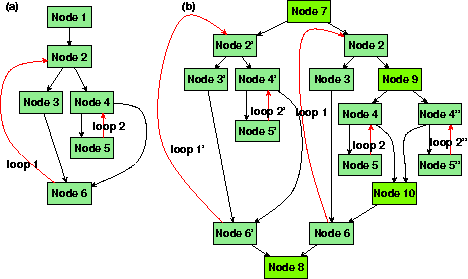
Der Compiler COMRADE wählt automatisch Regionen eines Quellcodes aus, welche einen Laufzeitgewinn in Hardware versprechen. Das sind im allgemeinen innerste Schleifen. Die Hardware-Auswahl von COMRADE hingegen versucht, auch mehrere geschachtelte Schleifen für die Hardware-Beschleunigung zu verwenden.
Dies geschieht in drei getrennten Schritten. Im ersten Schritt werden alle Schleifen dupliziert (Bild 15), für die aufgrund von Profiling-Daten eine Beschleunigung durch die Hardware-Ausführung zu erwarten ist. Hierbei können auch mehrere geschachtelte Schleifen dupliziert werden.
 |
| |
| Bild 15: Duplizierung von Schleifen für Hardware-Regionen |
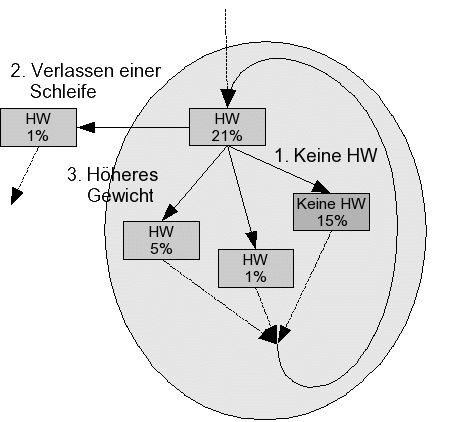
Zwischen diesem und dem folgenden Schritt der Hardware-Auswahl wird die Markierung aller Operatoren mit hardware-relevanten Daten in den duplizierten Regionen durch einen Compilerschritt vorgenommen. Der zweite Schritt sucht nach Pfaden in den Regionen, welche sich für die Hardware-Implementierung eignen. Dabei müssen mehrere Forderungen erfüllt sein (Bild 16). Zum ersten sollen nur Blöcke verwendet werden, die in Hardware realisierbar oder ohne Bedeutung für die Hardware-Ausführung sind. Blöcke, die z.B. nur die Zuweisung einer Konstanten an eine Variable besitzen, sind unbedeutend für die Hardware-Ausführung.
 |
| |
| Bild 16: Auswahlkriterien für Pfade in Hardware-Regionen |
Weiter soll der aktuelle Pfad auf dem kürzesten Weg zu einem Ausgang der Hardware-Region führen. Dadurch wird verhindert, dass beispielsweise in verschachtelten Schleifen alle Pfade einer inneren Schleife der Hardware zugeordnet werden, aber der Pfad keinen Ausgang der Region enthält. Solche Blöcke wären nicht in Hardware realisierbar, da auf jeden Fall ein Ergebnis von der Hardware an die Software zurückgegeben werden muss. Weiterhin sollen die Pfade eine hohe Ausführungswahrscheinlichkeit haben. Dadurch wird gewährleistet, dass hauptsächlich Teile des Quelltexts in Hardware übersetzt werden, welche einen hohen Geschwindigkeitsgewinn erzielen. Nur für gelegentliche Unterbrechungen muss in Software gewechselt werden. Der dritte Schritt der Hardware-Auswahl beurteilt alle Hardware-Regionen durch den zu erwartenden Laufzeitgewinn gegenüber der Software-Realisierung. Der Laufzeitgewinn bestimmt sich hauptsächlich durch die Anzahl der parallel ausführbaren Operatoren in der Hardware. Fällt der Laufzeitgewinn zu klein aus, wird die Software-Realisierung gewählt.
Tests an verschiedenen Programmen haben gezeigt, dass durch die Betrachtung mehrerer geschachtelter Schleifen ein höheres Potenzial an Laufzeitgewinn durch Hardware-Beschleunigung erreichbar ist.
Spekulative Ausführung von Datenflussgraphen in Pipelines
Die Ausführung der aus der DFCSSA-Form erzeugten Datenflussgraphen (DFG) auf der rekonfigurierbaren Hardware muss durch COMRADE geplant werden. Die DFGs enthalten verschiedene Typen von Operatoren. Statische Operatoren haben eine vorgegebene Laufzeit, dynamische dagegen werden mit einem Signal gestartet und signalisieren das Ende ihrer Operation. Neben diesen zwei grundsätzlichen Typen können auch Operatoren in den Datenflussgraphen auftreten, die beispielsweise interne Pipelines enthalten oder ihre Daten mit Hilfe von Protokollen austauschen.
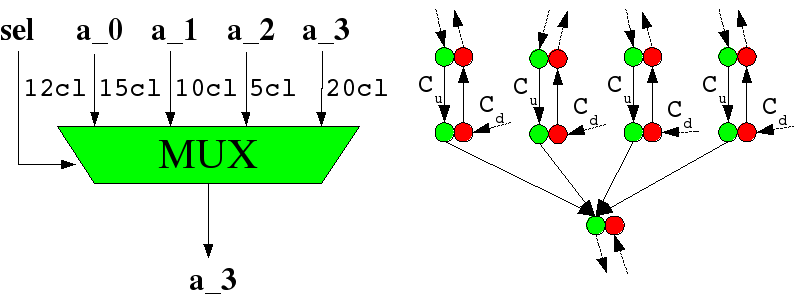
Vor allem das Vorhandensein von dynamischen Operatoren macht klassische Scheduling-Algorithmen wie kräftegesteuertes Scheduling unbrauchbar für den Einsatz in COMRADE. Diese Algorithmen können nur die längste Laufzeit benutzen, um die Operatoren einzubinden. Zur Lösung dieses Problems wird durch COMRADE für jeden DFG ein Petri-Netz erzeugt, welches die Ausführung des DFG steuert sowie auf Signale aus dem DFG reagiert. Der so erzeugte Controller startet eine Operation genau dann, wenn alle Eingangsdaten anliegen sowie alle nötigen Kontrollflussbedingungen zur Ausführungen der Operation vorhanden sind. Eine Operation wird natürlich nicht gestartet, wenn sie gerade rechnet. Die Ergebnisse von Operationen werden in Registern zwischengespeichert. Durch dieses Verhalten werden Daten schnellstmöglich verarbeitet. Es ist automatisch eine Pipeline entstanden.
Eine weitere Verbesserung der Laufzeit des DFG kann erreicht werden, wenn Operationen spekulativ ausgeführt werden. Hierbei werden Pfade im DFG spekulativ berechnet, wenn diese kein Ergebnis verfälschen können. Operationen wie Speicherzugriffe können demnach nicht spekulativ ausgeführt werden. In COMRADE wird die spekulative Berechnung immer dann benutzt, wenn ein Multiplexer aus mehreren Ergebnissen ein richtiges aufgrund von Kontrollflussinformationen aussucht. Alle anderen Berechnungen werden dann deaktiviert. Das Deaktivieren wird hierbei durch einen speziellen Zustand der Knoten im Controller erreicht, welche sich in Gegenrichtung des Datenflusses fortpflanzen können (Bild 17). Trifft dieser Zustand (Down) einen Zustand, der eine aktuelle Berechnung steuert (Up), so löschen sich beide aus. Die Berechnung wird also abgebrochen.
 |
| |
| Bild 17: Multiplexer mit dazugehörigen Up- und Down-Zuständen |
Rekonfigurations-Scheduling
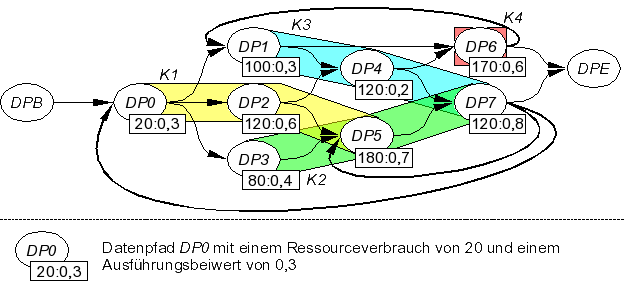
Die durch COMRADE erzeugten Datenpfade sind oft so klein, dass mehrere von ihnen gemeinsam zu einer Konfiguration für die rekonfigurierbare Logik zusammengefasst werden können. Auf diese Weise lässt sich die Anzahl von Rekonfigurationen verringern. Jede so vermiedene Rekonfiguration verbessert wegen der langen Rekonfigurationszeiten der meisten heute verwendeten Bausteine die ACS-Beschleunigung eines Programms erheblich. Grundlage für das Zusammenfassen von Datenpfaden zu Konfigurationen in COMRADE bilden Kontrollflussinformationen (Welcher Datenpfad muss nach welchem anderen geladen werden?) und Laufzeitinformationen (Wie oft wird ein Datenpfad benötigt?). Dazu wird ein so genannter Datenpfad-Ladegraph erzeugt, in welchem diese Informationen zusammengefasst sind (Bild 18). Der Datenpfad
DP1 verbraucht hier beispielsweise 100 Ressourcen und hat einen Ausführungsbeiwert von 0,3.
 |
| |
| Bild 18: Datenpfad-Ladegraph |
Durch eine Heuristik wird der Datenpfad-Ladegraph partitioniert. Jede der entstehenden Partitionen stellt eine Konfiguration für den rekonfigurierbaren Teil eines Adaptiven Rechensystems dar. Werden nun mehrere Datenpfade während einer Programmausführung hintereinander benötigt, können Rekonfigurationen weitgehend vermieden werden: Beim Test mit realen Programmen hat sich gezeigt, dass so bis zu über 99% der Rekonfigurationen eingespart werden können.
Bitbreiten-Reduktion und Evaluierung konstanter Bits
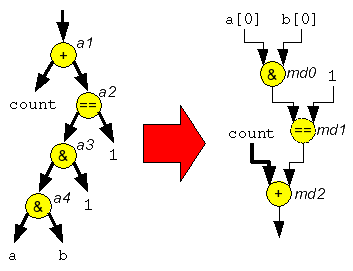
Bei adaptiven Rechnern kann nicht nur die Struktur des rechnenden Datenpfades an die Anforderungen der Anwendung angepasst werden, sondern auch die jedes einzelnen Operators innerhalb des Datenpfades. Für die Addition muss also nicht immer das gleiche Addierwerk verwendet werden, das variable Werte addieren kann, sondern es können für bestimmte Konstanten spezialisierte Additionsoperatoren erzeugt werden. Dazu werden nicht nur die konstanten, sondern auch die von jeder Einheit tatsächlich berechneten Bits verfolgt. Feiner als bei den C-Datentypen (z.B. Worte von 32 Bit, 16 Bit, 8 Bit) können in einem spezialisierten Operator auch innerhalb des "Wortes" unbenutzte Bits oder konstante Bits auftreten. Konstante Bits treten meist nach logischen Operationen auf oder nach dem Extrahieren von Werten aus gepackten Darstellungen (z.B. Datenpaketen bei Kommunikationsprotokollen. Ein Beispiel mag hier mehrere der potenziellen Optimierungen verdeutlichen.
// Endianness eines Wertes ändern, C-Beschreibung
unsigned char a[];
result = (a[i] << 24) + (a[i+1] << 16) + (a[i+2] << 8) + a[i+3];
In dieser Rechnung werden, nach C-Standard, die einzelnen Unsigned Chars aus dem Speicher erst auf die Länge von "int" gebracht (normalerweise 32 Bits), anschließend werden durch Shift-Operationen die Werte an die richtige Stelle des Zielwortes gebracht. Die einzelnen Resultate werden addiert.
Durch die Verfolgung von konstanten Bits, in diesem Falle je 24 konstante Nullen pro Einzelausdruck, kann hier jedoch keine Breite in den Datenworten eingespart werden. Immerhin, die erkannten konstanten Werte müssen nicht mehr berechnet oder über den Chip verdrahtet werden: Sie können direkt an ihren Konsumenten lokal angelegt werden.
Eine weitere Optimierung aus dem Bereich der Logiksynthese erlaubt aber eine weitere Verbesserung: Im Beispiel kann, da die einzelnen variablen Bereiche der Teilausdrücke nicht überlappend sind, kein Übertrag zwischen den drei Additionen entstehen (die obersten 24 Bit sind ja als Null erkannt worden). Deshalb kann in dieser Rechnung die gesamte Addition durch ein logisches ODER-Gatter ersetzt werden. Anschliessend wird die Wirkung der 24 konstanten Null-Bits auf dieses ODER-Gatter analysiert. Dabei wird dann ermittelt, dass die Funktion des Gatters in diesem Fall genausogut durch reine Verdrahtung berechnet werden kann, dass Gatter selbst kann also vollständig entfallen.
In einer Hardware-Beschreibungssprache wie Verilog würde diese Struktur am ehesten durch
// Endianness eines Wertes ändern, Verilog-Beschreibung
assign result [7:0] = a[i+3];
assign result [15:8] = a[i+2];
assign result [23:16] = a[i+1];
assign result [31:24] = a[i];
ausgedrückt. Arithmetik wird für diese Rechnung nun nicht mehr benötigt.
In weniger extremen Fällen lassen sich durch diese Vorgehensweise aber die Anzahl der Überträge (Länge der Carry-Chains) reduzieren und somit kleinere und schnellere Operatoren erzeugen.
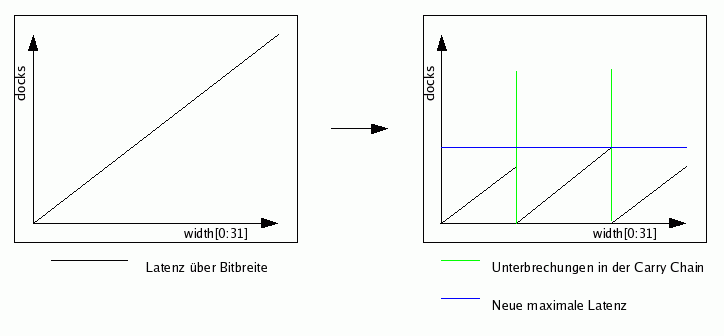 |
| |
| Bild 19: Aufbrechen von Carry-Chains |
Beschreibungsunabhängige Analysemethoden
Innerhalb des COMRADE-Compilers befindet sich ein Interface für Datenflussanalysen. Dieses Interface abstrahiert den kompletten Kontrollfluss von höheren Analysen ebenso wie viele Details des internen Aufbaus der Zwischendarstellung. Durch dieses "DFlow"-Interface ist es möglich, viele bestehende Methoden aus der Fachliteratur direkt zu benutzen.
Als Basisdarstellung werden Bitvektoren benutzt, die eine einfache Möglichkeit der Mengenoperationen bieten. Die meisten Algorithmen zur Datenflussanalyse basieren auf solchen Mengenoperationen. Als Basis der Berechnung dienen hier Attribute wie READ/WRITE auf Variablen. Diese Attribute müssen aus der internen Zwischendarstellung extrahiert werden. Aufbauend auf einigen solchen synthetischen Attributen können dann viele andere Attribute berechnet werden, wobei kein Zugriff mehr auf die interne Repräsentation nötig ist. Somit ist es einfach möglich, Analysen zu entwerfen, die unabhängig vom System sind. Durch die bessere Entkopplung wird nicht nur die Wiederverwendbarkeit der Analysen verbessert, sondern es werden auch Seiteneffekte vermieden. Es ist aus der Sicht eines Analysepasses nicht mehr ohne weiteres möglich, direkt die Zwischendarstellung zu ändern. Dies beugt Programmfehlern vor.
Metaoptimierungen für adaptive Rechner
Mit der Definition von ATS (Aggressive Tail Splitting) wurde ein neues Verfahren zur Optimierung von Programmen definiert. Es ist keine neue Art von Optimierung, sondern eine Metaoptimierung. Innerhalb einer Schleife wird jeder mögliche Programmablauf, auch über Schleifengrenzen hinweg, als eigener Ablauffaden aufgefasst. Hierdurch ergibt sich zwar eine Vergrößerung des Programms, durch diese Transformation wird es jedoch möglich, dass eine Reihe von Optimierungen besser durchgeführt werden kann.
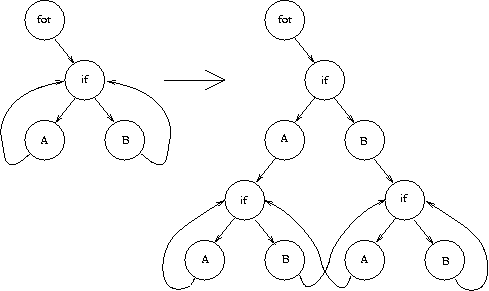 |
| |
| Bild 20: Beispiel für Aggressive Tail Splitting |
In Bild 20 muss vor jedem
A oder
B in der untersten Ebene auf der linken Seite des
if einmal
A ausgeführt werden. Auf der anderen Seite des
if muss vorher ein
B ausgeführt worden sein. Diese konstante Vorgeschichte kann zur Optimierung benutzt werden.
Unterstützung von spekulativer Parallelisierung auf einem adaptiven Rechner
Bei der spekulativen Parallelisierung wird davon ausgegangen, dass jeder der parallelisierten Abläufe keine Änderungen (Schreibzugriffe auf Variablen) ausführt, die einen anderen Ablauf beeinflussen. Trotzdem muss das Programm auch bei Verletzung dieser optimistischen Annahme korrekte Ergebnisse liefern. Dazu werden die Teilergebnisse jedes Ablaufs solange nur lokal gehalten, bis ein Konflikt mit einem anderem Ablauf definitiv ausgeschlossen werden kann. Erst dann werden die Daten freigegeben (also z.B. in den Speicher geschrieben). Im Falle eines Konflikts (erkannt durch spezialisierte Überwachungs-Hardware) wird dagegen der bisher gerechnete Ablauf verworfen und mit, von einem anderen Ablauf freigegebenen, modifizierten Daten neu gestartet.
Der Vorteil der spekulativen Parallelisierung liegt darin, dass sie auch dann durchgeführt werden kann, wenn eine statische Analyse des sequentiellen Programmtextes die nebenläufige Ausführbarkeit nicht garantieren kann. Als Nachteile sind die komplexere Hardware und der potenziell höhere Energieverbrauch durch das wiederholte Rechnen von Abläufen (aufgrund von Konflikten) zu nennen.
Auf einem adaptiven Rechner kann nun die Überwachungs-Hardware zur Erkennung und Auflösung von Konflikten gezielt auf die potenziellen Konflikte abgestimmt werden, die im realisierten Algorithmus auftreten können. Sie ist somit deutlich einfacher als eine universelle Implementierung.
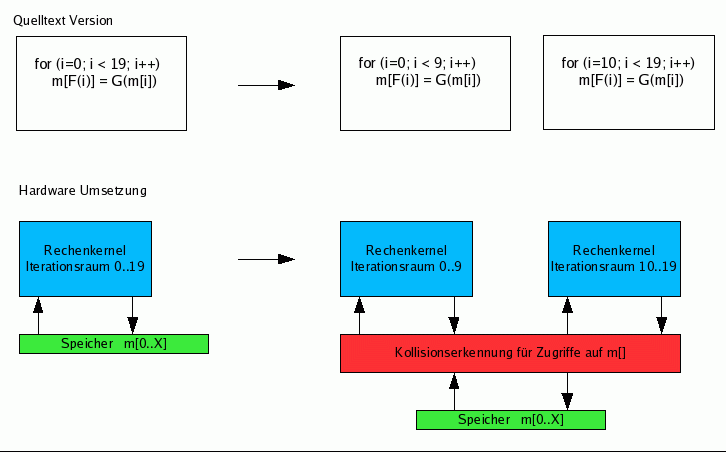 |
| |
| Bild 21: Spekulative Parallelisierung auf einem adaptiven Rechner |
Untersucht wurde neben der Erweiterung des Speichersystems MARC um die Konflikterkennungs-Funktionalität auch die Anwendbarkeit des vorgeschlagenen Verfahrens in Beispielprogrammen aus den unterschiedlichsten Anwendungsgebieten.
Einbindung komplexer IP-Blöcke in automatisch generierte Datenpfade
Neben der Verwendung relativ einfacher Operatoren, wie sie der Modulgenerator
GLACE bereitstellt, ist es aus mehreren Gründen sinnvoll, auch komplexere IP-Blöcke (Intellectual Property) nahtlos in automatisch generierte Datenpfade zu integrieren. Zum einen können extrem hohe Anforderungen an die Hardware-Qualität, z.B. zur Steigerung der Rechenleistung, die manuelle Optimierung eines Blockes erforderlich machen, der dann mit der restlichen kompilierten Anwendung zusammengebunden werden muss. Diese Vorgehensweise ähnelt der im Software-Bereich praktizierten Einbindung handoptimierten Assembler-Codes in größere C Programme. Zum anderen besteht die Möglichkeit der Wiederverwendung schon bestehender IP-Blöcke in einer neuen, in C formulierten Anwendung. Dies entspricht etwa den Bibliotheken im Software-Bereich.
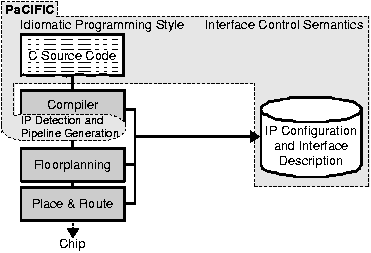
Um die automatische Integration der IP-Hardware zu ermöglichen, wurden zunächst die Schnittstellensemantiken von mehr als dreißig kommerziellen IP-Blöcken klassifiziert. Hierbei wurden sowohl abstrakte logische Konstrukte wie Datenströme, Speicherblöcke oder skalare/vektorielle Daten und ihre Formate und Raten untersucht als auch physikalische Schnittstelleneigenschaften wie Busprotokolle und Handshake-Verfahren. Anschließend wurde der Systemrahmen PaCIFIC (Parametric C Interface For IP Cores) definiert, welcher die Einbettung der abstrahierten Schnittstellenmechanismen in die Programmiersprache C realisiert.
Parametric C Interface For IP Cores (PaCIFIC)
PaCIFIC besteht aus Regeln für einen idiomatischen Programmstil, der beim Einbetten von IP-Blöcken in ein C-Quellprogramm angewendet werden muss, und Semantiken zur Schnittstellensteuerung, die das Schnittstellenverhalten eines IP-Blockes beschreiben (Bild 22). Dazu enthält PaCIFIC ein Datenmodell und eine menschenlesbare Beschreibungssprache für die Charakteristiken von einzelnen IP-Blöcken sowie ganzer Plattformen. Alle Komponenten sind in mehreren speziellen Compiler-Passes zusammengebunden, welche die notwendigen Analyse- und Syntheseschritte sowohl für die Hardware als auch die Software durchführen.
 |
| |
| Bild 22: Design-Fluss mit PaCIFIC |
PaCIFIC ermöglicht die automatische Kombination von IP-Blöcken und zur Hardware-Ausführung bestimmten Programmteilen (siehe
Compiler für adaptive Rechensysteme) zu einem Datenpfad und dessen Nutzung aus einer Software-Beschreibung heraus, die gleichzeitig Quelle und Senke für die Daten ist. Ein natürlicher Ansatz für reine Software würde die beiden IP-Blöcke als C-Funktionen betrachten. Aus einer Folge solcher Funktionsaufrufe wird die Hardware-Pipeline automatisch generiert. Dies erfordert zusätzliche Informationen über die Hardware-"Funktionen", z.B. das Schnittstellenprotokoll, oder welche Register mit welchen Werten programmiert werden müssen, um eine bestimmte IP-Funktion auszuführen. Die Informationen werden vom IP-Entwickler in o.g. Beschreibungssprache zusammen mit dem IP-Block in einer speziellen Bibliothek hinterlegt. Der Software-Entwickler benötigt folglich keine Kenntnis von den tatsächlichen Mechanismen, die an der Realisierung des Datenpfades beteiligt sind.
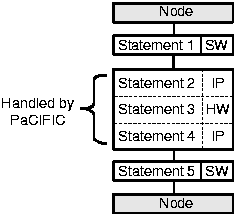
PaCIFIC ermöglicht COMRADE (Link), komplexe IP-Blöcke zu integrieren und auf diese zuzugreifen. Dazu wird COMRADE um zusätzliche Compiler-Durchläufe erweitert, die anhand der PaCIFIC-Beschreibung idiomatische Hardware-Funktionsaufrufe in einem C-Quellprogramm finden. Im ersten Durchlauf wird die interne Zwischendarstellung des C-Programms nach IP-Blöcken durchsucht. Sie werden im weiteren Verlauf nicht von den existierenden C-nach-Hardware Compiler-Durchläufen verarbeitet. Der die IP-Block-Aufrufe enthaltende Basisblock ist durch einen Knoten in der internen Darstellung repräsentiert. Dieser wird zwischen Software-Ausführung und automatisch synthetisierten Datenpfaden einerseits sowie IP-Block-Ausführung andererseits aufgeteilt. Anschließend wird die Zwischendarstellung nach Hardware-Pipelines durchsucht. Sie werden aus den automatisch kompilierten Hardware-Datenpfaden und im Kontrollfluss aus angrenzenden IP-Blöcken zusammengesetzt (Bild 23).
 |
| |
| Bild 23: Pipeline aus zusammengefassten Hardware-Knoten |
Plattformen und Systemkomposition
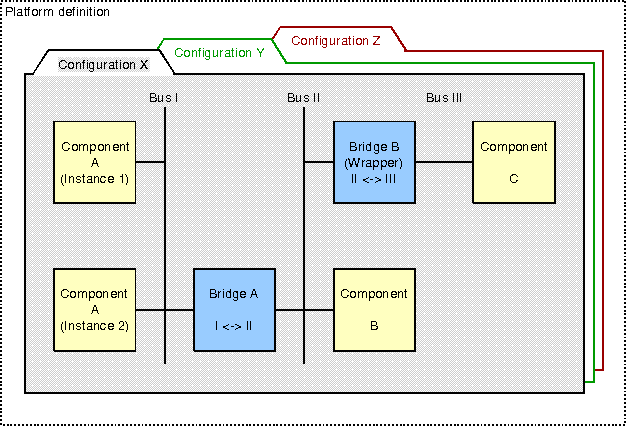
Plattformen spielen eine wesentliche Rolle beim Zusammensetzen (Komponieren) von Hardware-Systemen aus bestehenden Komponenten (Wiederverwendung, Re-use). Eine Plattform repräsentiert dabei eine Systemumgebung, in die eine oder mehrere Hardware- oder Software-Komponenten integriert werden. Im Rahmen dieser Arbeit wurden Möglichkeiten untersucht, Plattformen und Komponenten derart umfassend zu beschreiben, dass sie automatisch gemäß Anwendervorgaben zu Systemen komponiert werden können.
 |
| |
| Bild 24: Struktur einer Plattformdefinition |
Der konkrete Aufbau des Systems wird durch die Plattformkonfiguration bestimmt. Diese beschreibt jede verwendete Komponente und ihre speziellen Eigenschaften (in der Regel durch Parameterwerte). Die Plattformkonfigurationen sind der zentrale Bestandteil einer Plattformdefinition. Es können mehrere alternative Konfigurationen existieren. Sie bestehen im wesentlichen aus Instanzierungsbefehlen für Komponenten oder Busbrücken. Eine Komponenteninstanzierung bindet einen Block mit seiner vollen Funktionalität an die Plattform. Im Gegensatz dazu erwartet die Busbrückeninstanzierung einen Block, der nur Adressübersetzung und Datentransfer zwischen seinen Schnittstellen bietet. Die Plattform wird durch Verbindung der Schnittstellen aller instanzierten Blöcke zusammengesetzt, wobei ein Schnittstellenbindungsmechanismus verwendet wird, der Designs durch Verbindung von Schnittstellen mit zueinander passenden Charakteristiken automatisch zusammensetzt. Die Schnittstellenbindung ist ein schrittweiser Prozess, welcher gestartet wird, wenn die Plattform oder das Design für den späteren Gebrauch zusammengestellt wird. Jede initiierende Schnittstelle, d.h. diejenige, die ein passendes Gegenstück sucht, wird nach und nach mit einer Zielschnittstelle verbunden.
Auf diese Weise lassen sich auch komplexe Systeme automatisch durch Anwendung einer Regelbasis geleitet durch die Benutzeranforderungen erstellen.
Allgemeine Einführung in adaptive Rechensysteme
Moderne Fertigungstechniken erlauben zwar die Herstellung immer größerer Chips, auf der anderen Seite wird aber jeder einzelne Fertigungslauf (von der Maskenerstellung zum Test) auf einem solchen Prozess immer aufwändiger und damit für immer weniger Neuentwicklungen rentabel.
Ein Ausweg aus diesem Dilemma kann der Einsatz von programmierbaren bzw. konfigurierbaren Schaltungen sein, bei denen eine feste Chip-Plattform durch nachträgliche Anpassung auf die konkrete Anwendung zugeschnitten werden kann. Neben der allgemeinen Kostensenkung durch Zugriff auf einen Massenbaustein können durch das so erreichbare hohe Maß an Anpassbarkeit Änderungen (z.B. während eines Normungsprozesses) ohne Risiko in den laufenden Entwurf einfließen.
Die hohe Flexibilität von Standardprozessoren, deren Anwendung rein durch Software definiert ist, wird häufig durch den Zwang zur Überdimensionierung des Prozessors erkauft: Einzelne Funktionen der Anwendung, die sich möglicherweise effizient direkt in Hardware implementieren lassen, können rein in Software weniger gut realisierbar sein und erfordern zum Ausgleich einen insgesamt leistungsfähigeren Prozessor. Eine universell einsetzbare Lösung sollte daher neben der Software-Flexibilität auch in Hardware-Aspekten anpassbar sein.
Das Spektrum dieser Anpassbarkeit reicht dabei von einmalig (für die gesamte Lebensdauer der Anwendung), mehrmalig (mehrere Änderungen über die Lebensdauer der Anwendung) bis hin zu dynamisch (mehrfach wärend der Ausführung der Anwendung). Im ersten Fall werden in der Regel nicht-flüchtige Bausteine (z.B. antifuse-basierte FPGAs) vor Auslieferung einmalig auf den aktuellen Stand der Anwendung zugeschnitten. Beim zweiten Szenario besteht die Möglichkeit, auch einen bereits ausgelieferten Baustein (z.B. ein EEPROM-basiertes FPGA) noch anzupassen. Diese Möglichkeit kann auch für Updates auf Hardware-Basis verwendet werden.
Adaptive Rechensysteme gehören zum dynamischen Fall. Hier werden die Hardware-Funktionen zur Laufzeit an die Bedürfnisse der Anwendung angepasst. Selbst für einzelne Programmphasen oder -modi (z.B. Kompression, Dekompression etc.) können optimierte Funktionen in Hardware bereitgestellt werden. Diese Anpassung kann dabei so weit gehen, dass die Hardware-Funktionen sogar noch auf die im aktuellen Lauf verwendeten Daten spezialisiert werden (z.B. den konkreten Schlüssel für ein Krypto-Verfahren).
Adaptive Rechensysteme basieren auf Technologien, die heute neben den klassischen FPGAs (die mittlerweile ausreichende Kapazitäten für reale Rechenanwendungen bereitstellen) und anwendungsspezifischen Prozessoren (ASIPs) insbesondere auch sogenannte Network Processors umfassen. Letztere haben als konfigurierbare Einheiten in der Regel keine 1-bit-breiten Logikblöcke, sondern bauen auf Multi-Bit-Operatoren wie ALUs auf.
Entscheidende Leistungssteigerungen mittels adaptiver Rechner lassen sich nur erreichen, wenn die Werkzeuge im Entwurfsfluss schon auf hoher Ebene auf die Zielplattform hin optimieren. Dabei darf ein praktisch anwendbares System nicht die Anforderungen seines potentiellen Nutzerkreises aus den Augen verlieren: Zur Eingabe sollten dem Nutzer vertraute Notationen zum Tragen kommen, im DSP-Bereich also beispielsweise C, Fortran und MATLAB. Die Verwendung exotischer Eingabesprachen (und dazu zählen aus Sicht eines Software-Entwicklers auch HDLs!) wäre der breiten Anwendung eher hinderlich.
Bei dieser software-artigen Flexibilität der Hardware (gelegentlich auch Soft-Hardware oder Agileware genannt) kommt es zwangsläufig zu einer sehr engen Verzahnung von Hard- und Software-Aspekten.
Hardware-Architekturen und passende
Entwurfswerkzeuge müssen sorgfältig aufeinander abgestimmt werden. Eigenschaften der Hardware beeinflussen die Algorithmen der Entwurfswerkzeuge. Umgekehrt erfordern verschiedene Vorgehensweisen der Werkzeuge auch die Bereitstellung bestimmter Hardware-Fähigkeiten.

 Research Portfolio (English Description)
Research Portfolio (English Description)