Outline
Adaptive Computing Systems: Architecture and Design Tools
Adaptive computing systems can be customized not only by executing appropriate software, but also by adapting certain hardware aspects of the system to better handle the current computational problem. This degree of flexibility requires novel design tools that simultaneously optimize both the hard- and software components of an algorithm. Please refer to the
General Introduction for an overview of the underlying technology.
The current research of the Embedded Systems and Applications (ESA) group is based on prior work at the
Department of Integrated Circuit Design (E.I.S.) of the Technical University of Braunschweig. Since 1997, E.I.S. has been collaborating with the Advanced Technology Group of Synopsys Inc. and the
BRASS group of UC Berkeley in context of the project "A Nimble Compiler for Agile Hardware". This effort aims at a continuous design flow that can efficiently translate C programs into hybrid HW/SW applications executable on adaptive computing systems. While this joint project was successfully completed in 2001, our own efforts in this area continue.
The successor to Nimble, COMRADE, made significant progress in 2004. It is now able to compile the first complete sample applications from C down to simulated hardware. The compile flow was further refined by adding novel optimization passes such as Aggressive Tail Splitting and bit-width reduction. These topics are treated as part of a DFG (German national science foundation) project that also considers the automatic integration of existing hardware blocks with the compiler-generated datapaths.
Architectures for Adaptive Computing Systems
 |
| |
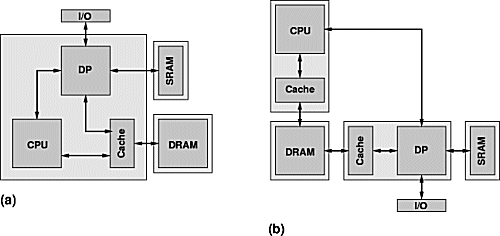
| Figure 1: Hardware Architectures |
| (a) single-chip (ideal, e.g., UCB GARP), (b) multi-chip (real, EIS/Synopsys ACEV) |
Adaptive computing systems (ACS, see also the
General Introduction) rely on hardware components that allow the implementation of different user-specified circuit designs at run-time. Thus they can be adapted to the requirements of the currently executing algorithm. However, even in an ACS, the majority of components is of the fixed-function (non-reconfigurable) variety. As in conventional computer architecture, the initial design choices concerning the static aspects of the system have to be made with great care, since they cannot be changed afterwards. To this end, one of our research areas deals with the design, realization, and evaluation of hardware architectures for ACSs.
In our current view, an ideal target system for our design flow would have an architecture similar to that shown in Figure 1(a): A reconfigurable data path DP is tightly coupled (low latency communication) to a conventional CPU. Both units access shared memories (DRAM, Cache). The DP may optionally also have local memories (SRAM) and I/O ports.
The data path should have a capacity to simultaneously implement dozens to hundreds of ALU operations. Sufficient flip-flops should be available to allow deep pipelining of the circuits. The system performance is highly dependent on the configuration speed of the DP: The precious silicon area required to implement the reconfiguration capability can only be used efficiently when frequent reconfigurations are actually feasible in practice.
Since appropriate single-chip solutions are only slowly becoming available (Altera Excalibur, PACT XPP, Xilinx Virtex-II Pro), we implemented a board-level experimentation and evaluation platform using discrete components.
 |
| |
| Figure 2: Base PCB of the ACE-V adaptive computing system |
The ACE-V system is implemented as a PCI expansion card hosted in a SPARC workstation. A Xilinx Virtex XCV1000 FPGA holds the reconfigurable data paths while a microSPARC-IIep RISC acts as CPU. DP and CPU share 64MB of DRAM. Another 4 banks of 1MB ZBT-SRAM each are local to the DP for use as scratch pad memories etc. CPU and DP communicate via an on-board PCI bus (separate from the host bus). To reduce the long latencies for PCI-based memory accesses, the DP routes these through a dedicated L1 cache. Since no computing system is complete without software, we ported the RTEMS real-time operating system to the board. In this manner, both the ACE-V hard- and software can execute independently of the host.
Host and ACE-V communicate only for access to peripheral devices (disk, network, terminals). This environment allows the practical evaluation of design tools, hardware architectures, firmware implementations, and actual end-user applications much faster than it would be possible using simple simulations. Furthermore, many issues are discovered only when taking a system-level view at a real-world computer that would be missed in the reduced scope covered by simulations.
Unfortunately, the current board-level architecture, specifically the high-latency PCI bus between DP, CPU, and memory, limits the absolute computing performance of the platform. The slow reconfiguration rate of the Virtex device also hinders the efficient re-use of the configurable logic area. Once we can actually switch to a more integrated single-chip architecture, these performance limitations will be lifted.
By now, the ACE-V platform is sufficiently stable to be accessible to a broader user base.
Since reconfigurable devices with a higher degree of integration have become available, we have begun the migration of our systems to a more modern platform in 2004. Specifically, we are aiming at the Xilinx Virtex II Pro series of System-FPGAs. These devices integrate up to four RISC processor cores with tens of thousands of reconfigurable logic blocks on a single die. Our porting effort has begun with establishing an appropriate operating system and programming environment on a AlphaData ADM-XP configurable processing board under Linux.
Design Flows for Adaptive Computing Systems
Currently, most ACSs are programmed manually in a rather tedious fashion: The original algorithm must be partitioned into hard- and software components, which are then implemented separately using completely different tool flows.
Additionally, the programmer has to design the interfaces and communication protocols on a per-application basis. Since each of these steps can be quite complex, programmer productivity for an ACS is rather low. This is one of reasons that ACS technology has not found its way into mainstream use yet.
As an alternative, we are working on a unified design flow that is closer to a pure software compilation process. The tools should either be able to work fully automatically ("push-button") or at least assist the human programmer as far as possible
The ultimate goal is a tool chain able to translate an algorithm formulated in a high-level language into an efficient hardware/software solution. The first prototype, called the Nimble Compiler, was built in collaboration with the Synopsys Advanced Technology Group and the BRASS group of UC Berkeley. Nimble compiles C programs into HW/SW executables that can be run on the
ACE-V platform. The core of the Nimble design flow (shown in Figure 3) is composed of an ANSI/ISO-compatible C Compiler and a combined data path synthesis and layout tool.
 |
| |
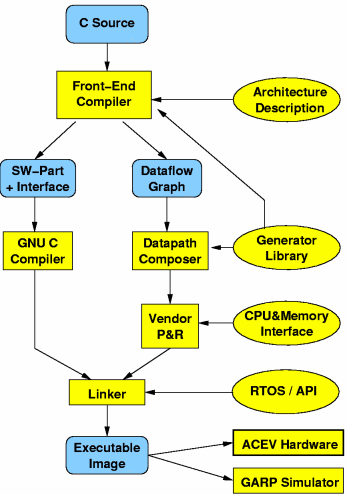
| Figure 3: Nimble design flow |
Similarly as in the manual flow, the C algorithm is initially partitioned into hard- and software parts. These decisions are based on a number of profiling runs that measure characteristics such as reconfiguration counts in addition to the usual per-block run times.
The blocks allocated for software execution are then extended by automatically adding interface code to the hardware components. Next, they are processed by a conventional software compile flow (GCC). The hardware parts of the algorithm are exported to the DatapathComposer as control-data flow-graphs for scheduling and placement.
Module generators are used to encapsulate all target device-specific data.
They are consulted both by the Compiler as well as by the DatapathComposer for timing and area information (among others). Finally, both hard- and software parts are linked together into single executable program, ready for execution on the
ACS (currently ACE-V, later also based on Virtex-II Pro).
Flexible Module Generator Interface
One focus of our work in
design flows for
Adaptive Computing Systems is on device-specific module generators and their outside interfaces.
Module generators actually create the circuits for the hardware components of an application, taking the specific needs (e.g., bit widths, data types, etc.) of the current algorithm into account. Due to the flexibility of current generators and the amount of meta-data available (information about the circuits), the nature of the design flow - generator interface has a major influence on the rest of the flow as well as on the performance of the executables it creates.
To this end, we rely on the Flexible API for Module-based Environments (FLAME), which is the result our previous research. This specification defines the exchange of detailed information (both circuits and meta-data) between the tools of the main design flow and the module generator library.
 |
| |
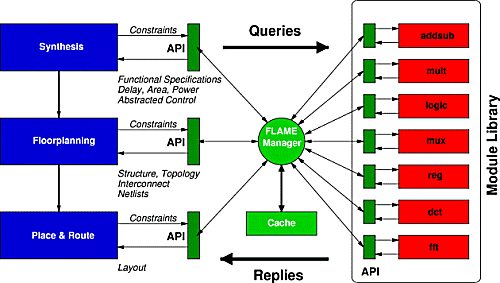
| Figure 4: FLAME Interface |
As shown in Figure 4, existing module generators can be wrapped with a FLAME-compliant interface for use in a FLAME-based environment. This makes them available to arbitrary design tools that rely on the FLAME Manager for their interactions with the generators. For example, the compiler or synthesis tool can use an appropriate query to determine which functions are actually available on the target device and how they are to be driven from the central controller. A data path floorplanning tool could determine layout and topology data for its own optimization decisions. The circuit itself can be retrieved in various forms (e.g., netlist, pre-placed layout etc.). In this manner, FLAME offers each design step a specific `view' into the generator library.
In 2001, we realized a first complete module library using the FLAME interface. GLACE, the Generic Library for Adaptive Computing Environments, contains a full set of operators for compiling high-level languages such as C into hardware. These operators are available for both the XC4000 and Virtex FPGA targets and are automatically characterized in terms of their delay, area and topology for the actual instantiation parameters values. Represented using FLAME, this information can be used by higher-level design tools such as compilers are floorplanners for the optimization of entire datapaths.
 |
| |
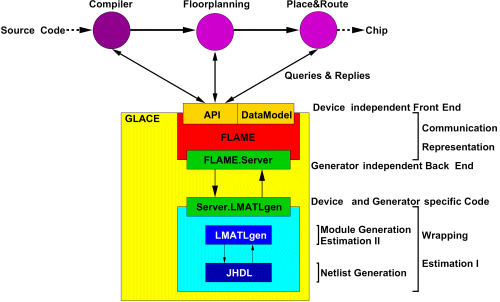
| Figure 5: GLACE |
Figure 5 shows GLACE, the Generic Library for Adaptive Computing Environments, which is the first FLAME-compliant module library. GLACE contains hardware implementations for all operators commonly required when translating a high-level programming language. In the current version, both the Xilinx XC4000 and Virtex architectures are supported as hardware targets. Main design flow tools can access the entire library functionality via the FLAME interface. This also includes retrieval of characteristics such as timing, area, control interface and layout topology in addition to the actual circuit netlists.
The FLAME Specification was further refined in 2004 and exhaustively published in the form of a Technical Report.
Floorplanning tools for Datapath-oriented Circuits on FPGAs
After creating circuits for individual operators of a data flow graph, these separate elements must be assembled into a complete hardware datapath. To this end, the characteristic aspects of both the original data flow graph and the hardware target technology must be considered. On the datapath side, this includes issues such as multi-bit operators, pipelining, hierarchical controllers, etc.), while on the target side, topics such as logic block architecture, special hardware support for arithmetic, and distributed memory should be addressed.
 |
| |
| Figure 6: Floorplanning |
In 2004, work started on a novel tool combining the traditional floorplanning operation with the merging of multiple individual datapaths into a single configuration. The latter process is based on the results of the
reconfiguration scheduling pass and can significantly reduce the reconfiguration overhead of a complex application while improving the usage of available reconfigurable capacity.
Evaluating Representative Applications on Adaptive Computing Systems
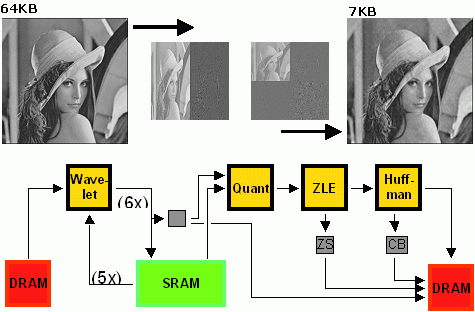
The impact of design choices for hardware architectures and algorithms for design tools can only be evaluated conclusively when using real applications as test subjects. To this end, students in the ACS research group implemented a complete representative sample application, going from an algorithmic description down to a hybrid hardware-software realization. The application has a pure data flow structure and realizes image compression using the Wavelet approach (which is also used, e.g., in the JPEG 2000 standard).
 |
| |
| Figure 7: Image compressions using the Wavelet approach |
The gray-scale input image will first be subjected to alternating horizontal and vertical filtering. This separates the low-frequency parts (="important image regions") from the high-frequency parts (="less important details"). A quantization step maps these coefficients to a smaller range of values. Many of the details less visible to the human eye will thus be mapped to the value of zero. These long runs of zeroes are then passed through a specialized run-encoder that converts them into a length specification ("15x zero"). The entire data stream is finally handed to a Huffman coder that translates common bit sequences into shorter codes. An actual implementation of this algorithm on the ACE-V, clocked at 31 MHz, requires 7.2ms to process a 256x256 pixel image. The Athlon XP CPU with a clock frequency of 1533 MHz takes just 4.2ms for the same task, but has a power consumption of 54-60 W. Even a processor optimized for low power consumption such as the Pentium-M still consumes 22 W. According to simulation data collected during a complete compression run, the reconfigurable compute unit on the ACE-V consumes just 0.8 W. As stated before, computation performance could at least be tripled using a current Virtex II Pro device at a similar level of power consumption (due to lower supply voltage and shrunk circuit geometries).
Evaluation Tools for Coarse-granular Reconfigurable Architectures
In cooperation with an industrial research partner, we developed a suite of parameterized placement and routing tools that rely on a flexible architecture description to quickly evaluate the capabilities of entire families of coarse-granular reconfigurable arrays. With the insight gained, the architecture variation best suited for the target application domain can be determined before committing it to silicon. The many parameters considered include the number and function of individual reconfigurable function blocks as well as their arrangement and interconnection. Further optimization for high throughput and/or low latency is achieved by modeling different kinds of pipelining.
Compiler for Adaptive Computing Systems
One of the most complex components in a
design flow targeting
Adaptive Computing Systems is the central compiler. The demands on such a tool exceed those posed on a conventional software-only compiler. In addition to common operations such as parsing, code-generation, optimization, etc., an ACS compiler must be able to partition the program into hard- and software components. Furthermore, the code generation phase encompasses generating instructions for a conventional (fixed-architecture) processor as well as the creation of optimal architectures for each of the hardware-allocated parts of the program.
In the latter case, different architectural styles might be used for different parts of the application. For example, a vector architecture might be used for one block of the applications while others could execute more efficiently on super-scalar or pure data-flow hardware. By relying on the reconfiguration abilities of an ACS, each block can be realized using the optimal style.
The reconfiguration frequency during the execution of an ACS application is limited by the configuration load times of the underlying hardware components (FPGAs, network processor, etc.). Thus, an ACS compiler has to consider the configuration transitions as part of its optimization loops. For example, it might be more efficient to allocate fewer blocks than actually possible to hardware in order to reduce configuration `thrashing' between them.
 |
| |
| Figure 8: COMRADE compiler architecture |
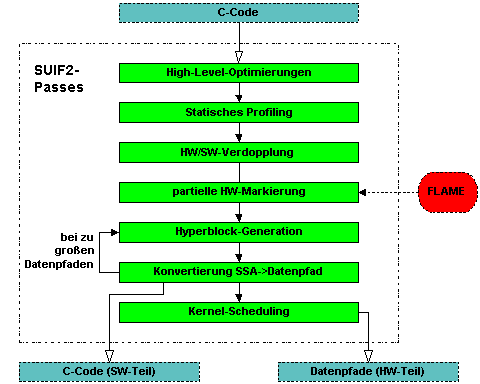
The recently initiated project `Compiler for adaptive systems' (COMRADE) is our second-generation attempt of creating a compiler system targeting ACSs from a high-level language. Figure 8 sketches the architecture of the core compiler.
Beyond classical techniques such as memory access optimizations (e.g., scalarization) and control flow-based profiling, more recent methods are being applied. These include hyper block representations using the static-single assignment form (SSA), which is very amenable for handling hardware-targeted code segments, and ACS-specific cost functions.
The compiler chooses operations for a later HW implementation at a representation level similar to C. Here, high level constructs such as while loops and if branches are still existent in the intermediate representation (IR). Now, an annotation pass determines various HW characteristics (delay, area, etc.) for all atomic operations (e.g., additions, multiplication, etc.). The actual HW/SW partitioning, which occurs at a later phase, relies on the information collected here. The HW characteristics of the individual atomic operations will not be affected by the later transformations (e.g. loop unrolling, dismantling of switch statements to if statements). Hence, this step can proceed at an early compilation stage. The source for the operator HW characteristics is the module generator GLACE, which also provides estimates in addition to the module netlists. Access to these services is offered by the interface FLAME. In addition to the HW characteristics, the partitioning relies on profiling results for its decision. Because the reconfiguration of HW and value transfer between HW and SW slow down various parts of HW implementation, it is not worth to implement all regions in HW. Only loops with high execution frequencies should be candidates for HW execution. All data paths of a program have to be loaded into the reconfigurable HW during the program run. Often, these data paths are small enough to place more than one at the target HW at the same time. The compiler schedules the reconfiguration of the data paths under various constraints. That guarantees a good usage of all HW ressources.
Intermediate representation for hardware selection and data path synthesis
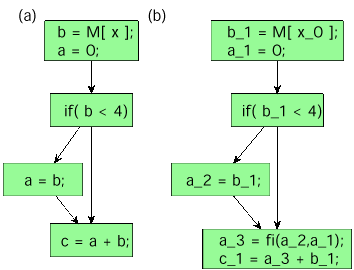
The hybrid HW/SW compiler we propose relies heavily on a suitable IR: The IR must be able to easily represent the source language at multiple abstraction levels as well as efficietly describe data and control flow even when subjected to complex transformations. For COMRADE, we extended a special form of control flow graphs: the static single assignment form (SSA form). When representing a program in SSA form, every write access to a variable leads to the creation of a new name for the destination variable. Because normal programs do not have this property in common, we have to convert programs to this form (Fig. 10).
 |
| |
| Figure 10: Control flow graph: a.) common form, b.) SSA form |
At nodes where multiple definitions join to create a single definition, so-called Fi statements are inserted to merge the appropriate variable definitions. These Fi statements lead to the creation of multiplexers in a later DFG creation pass. Thus, several values for one variable could be calculated in parallel. The multiplexer chooses the right value depending on control flow information.
Calculations of unneeded values can be safely aborted. In DFCSSA (data flow controlled SSA) form which is used in COMRADE Fi statements are only placed where the variable values are actually read. So, Fi statements with more than two inputs can be generated. These statements lead to more optimal multiplexers at the target HW. Furthermore, the DFCSSA translation can be concentrated only on the parts of the CFG that will end up in HW. Thus, COMRADE is working with a partial DFCSSA representation which keeps the SW regions of the CFG untouched. In this way, transformation (e.g., matching operator and variable bit widths to the specific data at hand) can be limited to HW regions. That reduces the compilation time.
Module generator access
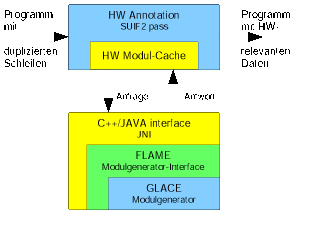
The HW/SW partitioning algorithm has to decide which program blocks should be realized in HW and which in SW based on information on the target HW. To keep our approach flexible and easily extendable, we rely on FLAME and its current implementation GLACE. For the access of HW information, we use an operator map which maps operators of the SUIF2 compiler system to behaviors offered by the formal description of FLAME. Connected with other structural factors like the number and type of ports, GLACE returns an exact description of the HW cells for this operator if available. With the help of these data we can ask for synthesis data using the synthesis request level of FLAME. The delay of a module and ist used area are now available for time and area estimations. The implementation of the HW annotation is done by a C++/JAVA system. The inner structure is shown in Figure 11. The C++ functions in the SUIF2 compiler pass use the JAVA capabilities with the help of the Java Native Interface (JNI). Programs contain a lot of equal operations. To build a request to FLAME for every single operation in the source program would waste time for repeating accesses to the module library. To prevent the time consumption we created a database which caches HW cell data and thus speeds up data collection.
 |
| |
| Figure 11: Access to module library GLACE |
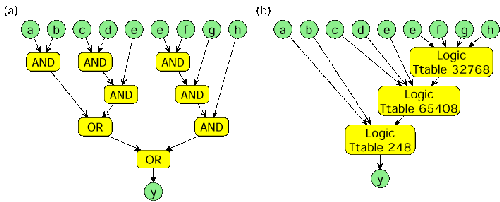
In practical use, this approach leads to a considerable reduction in GLACE accesses: at least 77% of module generator accesses could be avoided when compiling a set of sample applications. Module generators are able to create modules for a lot of operators in C. But sometimes, the compiler has to synthesize modules by itself. E.g., the compiler decomposes large multiplexers into balanced trees of multiplexers with only two inputs optimized to make efficient use of the cells actually available for a given device. A second area where the compiler has to apply intermodule techniques not applicable to individual generator (due their scopes being limited to a single module instance) is the implementation of logic functions. The logical operators in a high-level languages such as C are generally binary operators. More complex logic expressions are then constructed by composing these binary operators into larger terms. When naively mapping such a term to a coarse-grain configurable device such as 4- LUT based FPGA, with each SW operator becoming a separate HW operator, the resulting data path will be very inefficient. Consider the example shown in Figure 12a. The software term
y = (((a & b) | ((c & d) & e)) | (((e & f) & g) & h)
is mapped 1:1 into HW operators. The optimized version in figure 12b only needs 3 CLBs with 4 inputs instead of 7.
 |
| |
| Figure 12: Optimization of logical operators |
Compile time optimizations for adaptive computing systems
Beside classical methods as the optimization of array accesses and control flow based profiling, special methods for the target HW are needed. Mainly, pipelining of program execution is used to produce parallelism in created data paths. This is done automatically by the compiler.
Most time of a program is spent in loops. As a rule of thumb, there are 90% of the time spent in 10% of the program. It is therefore logical, while improving performance, to focus on these 10% of the code. But since the properties of AHS are quite different from those of standard hardware, established optimizations are not likely to carry the same impact. Therefore, it is necessary to re-evaluate those optimizations, as well as invent new ones aimed specially at adaptive computing systems.
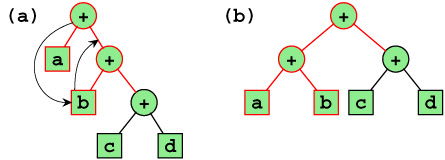
Some optimizations could be done at a high representation level of C source code. The internal representation in the compiler system is an abstract syntax tree. Here, expressions could be generated which did not have minimal delay in the resulting data path, e.g., if the statement
e = a + b + c + d is read in a tree with height 3 would result. A better realization is a tree which arises from the term
e = ((a + b) + (c + d)) and has the tree height 2. The perfect determination of the right tree needs to much calculation power. In COMRADE, we use heuristics which benefit from associativity and commutativity of operators. This algorithm uses local transformations of the syntax tree in cases when it is worth to do that for tree height reductions.
 |
| |
| Figure 13: Tree height reduction |
We do not get the most optimal result in all cases but a better runtime of the compiler.
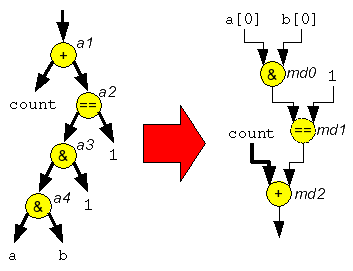
Very efficient for reducing the hardware area of the generated datapaths is the reduction of the bit-width of the operators, however. By considering the width characteristics of arithmetical and logical operators and propagating it in an expression tree, the width of the operator can be matched perfectly to the width of the data. E.g., the addition of two 8 bit numbers has a 9 bit result, the logical and of two 32 bit numbers has a 1 bit result, and so on. In some cases, one or more operators can be completely replaced by wiring (e.g., a multiplication by two becomes just a shift in the connections).
 |
| |
| Figure 14: Bit width reduction for shrinking the required area |
Hardware-Software-Partitioning
The compiler COMRADE automatically chooses regions of the source program which could be speeded up by hardware execution. Normally, innermost loops are taken for this purpose. COMRADE also tries to use nested loops for hardware acceleration. That is done in three steps (Figure 15). The first one duplicates all loops which are worth to be translated to hardware because of profiling data.
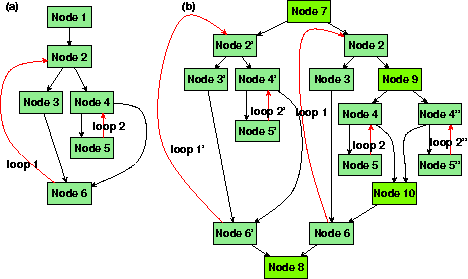 |
| |
| Figure 15: Loop duplication in hardware regions |
Between this and the next step, all operators in duplicated regions are annotated by hardware relevant data. The second step chooses paths in control flow graphs in duplicated regions which are well suited for hardware execution. Blocks on these paths should have only operations which are executable in hardware. Furthermore, COMRADE tries to search short paths from the entry point to any of the exit point of duplicated region. In this way we can assure that all data needed to exchange operators between software and hardware execution are placed in the region. The third important issue for the path creation is the execution probability of a block. Thus, only often executed regions are taken for hardware acceleration.
Speculative execution of data flow graphs in pipelines
The compiler COMRADE has to schedule the execution of data flow graphs (DFGs) which are created from all hardware regions. These DFGs contain different kinds of operations. Static operations have a constant delay. Dynamic operations are started by a signal and also signal the end of their execution. Furthermore, also pipelined operators are possible.
Classical scheduling algorithms as force directed scheduling cannot easily integrate dynamic operators. They would use maximum delays of these operators to integrate them. COMRADE solves the problem by adding a Petri net to the DFGs which controls the execution of the DFG. This controlling part only starts an operation when all input data are available and all control flow conditions are fulfilled. Furthermore, an operation cannot be started if it is still calculating. The results of all operations are stored in dedicated registers. Thus, data can be calculated as fast as possible. A pipeline was created automatically by COMRADE.
The controller also supports speculative execution of results. Only data flow paths without operations as memory accesses can be executed in this way. Results of speculative calculations are merged by multiplexers which choose one of the inputs as the correct result based on control flow information. All other calculations are deactivated. This is done by a special state which the controller can enter. These states (DOWN) can flow in the contrary direction of the data flow (Figure 17). If such a state meets a calculation (UP-state) this calculation is ended.
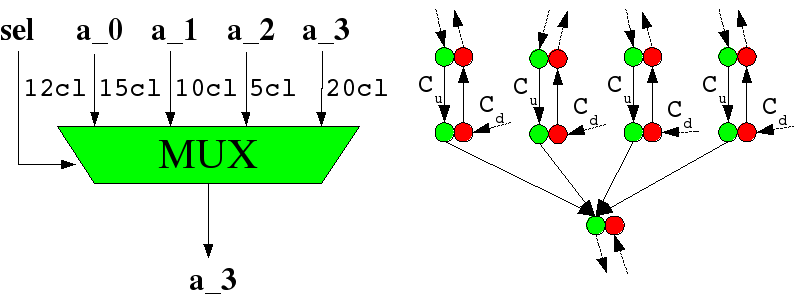 |
| |
| Figure 17: Multiplexer and controller with UP and DOWN states |
Reconfiguration Scheduling
Often, the datapaths generated by COMRADE are small compared to the entire capacity of a current reconfigurable device. To better exploit this area (which would go unused otherwise), reconfiguration scheduling attempts to pack multiple datapaths into a single configuration. The aim here is to use the entire available configurable area to reduce the number of reconfigurations.
This packing process must consider two dynamic characteristics of the program: The inter-datapath execution sequence and the time spent in each datapath (expressed as a so-called execution factor). Both of these can be derived from the dynamic profiling data collected earlier in the compile flow. As a static characteristic, the area requirements of each datapath also influence the assignment of datapaths to configurations. All of this information can be collected into a datapath configuration graph, an example of which is shown in Figure 18.
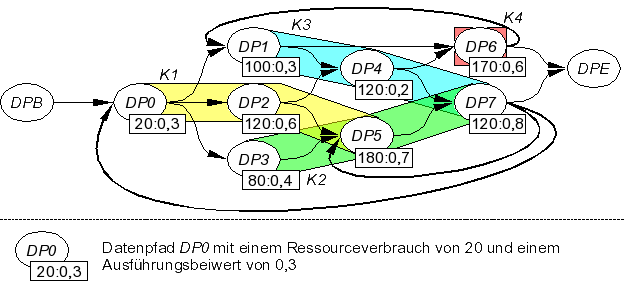 |
| |
| Figure 18: Datapath configuration graph |
This graph is then partitioned by a heuristic into (possibly overlapping) sub-graphs, with each sub-graph ending up as a single configuration. The aim here is to reduce the total number of reconfigurations across the typical execution behavior of the program. Tests using real-world sample applications resulted in a reduction in reconfiguration overhead in excess of 99%.
Operator bit width reduction and constant bit exploitation
Adaptive computers cannot only match the structure of the computing datapath to the needs of the current algorithm, but also the structure of each individual operator within that datapath. It is thus worthwhile to analyze the dataflow of the program not only in terms of the input language's native operand widths (e.g., for C integers: 32 bit, 16 bit, and 8 bit), but on the level of individual bits.
The characteristics of individual bits (e.g., constant, unused, active, directly generated from another bit) discovered in this fashion can then be exploited to simplify existing operators (e.g., realize conditionals as single-bit gates instead of 32 bit wide instances) or even to remove them entirely (replace a shift-add operation just by a permutation of wires).
Especially on fine-grained reconfigurable devices such as FPGAs, this can be exploited with good results. For a set of representative sample applications, the analysis discovered that only 60-75% of the bits of all variables are actually variable. The rest is either constant or unused (not read in the rest of the program).
In 2004, work has begun to fully integrate such a bit width reduction path into the COMRADE compile flow.
Description independant methods of analysis
Part of the COMRADE compiler is an interface for dataflow analysis. This interface decouples the flow of control from the higher analysis layers, as well as some details of the implementation. By using this "DFlow" interface, it is possible to use many well known algorithms from literature to be implemented right away. Because the basic data type used is the bit vector, logic operations on sets of variables are easily done. Most of the algorithms for data flow analysis are based on these logic operations. Attributes such as READ/WRITE are the foundation upon which more complex analysis is based. These basic attributes need to be extracted from the internal representation. When these basic attributes are provided, the more complex ones can be computed without knowledge of the internal representations.
This makes it possible to develop more sophisticated analyses which are independent from the internal representation of the compiler. This decoupling therefore improves code resuage and also shields the internal representation against modifications from a bug in an analysis module, thus preventing software bugs.
Metaoptimizations for Adaptive Computing Systems
With the definition of ATS (Aggressive Tail Splitting), a new kind of optimization was defined. ATS is not really a new optimization but a meta-optimization. Inside a loop, any possible flow of control is regarded as unique. This is done even across loop boundaries. While this increases the size of a program, it also allows for a lot of optimizations to be done much better.
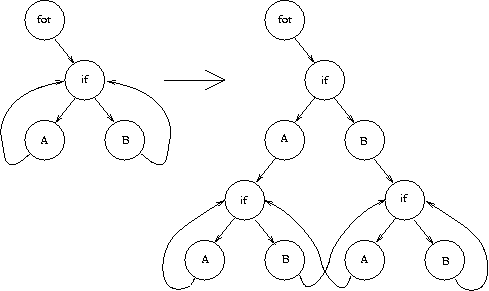 |
| |
| Figure 20: Aggressive Tail Splitting |
In Figure 20, before any "A" or "B" of the lowest layer is executed, there has to be one "A" executed on the left side of the "if" or one "B" for the other side. This constant history can be used to perform some optimizations.
Embedding Complex IP Cores into Automatically Generated Data Paths
Besides using relatively simple operators as provided by the module generator
GLACE, it is beneficial for several reasons to also seamlessly integrate more complex IP (Intellectual Property) cores into automatically generated data paths. On the one hand, extremely high hardware quality requirements, e.g., for increasing computing power, can demand the manual optimization of a core, which then has to be linked with the rest of the compiled application. This procedure resembles the embedding of hand-optimized assembler code into larger C programs which is common practice in the software domain. On the other hand, it is possible to reuse already existing IP cores in a new application formulated in C. This roughly corresponds to the libraries known in the software domain.
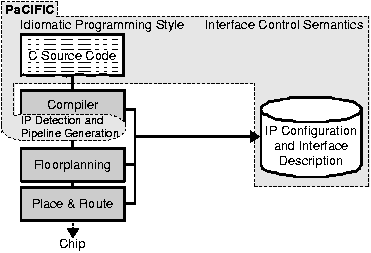
As a first step to enable the automatic integration of IP hardware, the interface semantics of more than thirty commercial IP cores were classified. During the investigation, both abstract logical constructs such as data streams, memory blocks or scalar/vectorial data and their formats as well as physical interface properties, e.g., bus protocols and handshake procedures were examined. Afterwards the PaCIFIC (Parametric C Interface For IP Cores) framework was defined which implements the embedding of the abstracted interface mechanisms into the C programming language.
Parametric C Interface For IP Cores (PaCIFIC)
PaCIFIC consists of rules for an idiomatic programming style which must be used when embedding IP cores in a C source program, and interface control semantics which describe the interface behavior of an IP core (see Figure 22). To this end, PaCIFIC includes a data model and a human-readable description language for the characteristics of individual IP blocks as well as entire platforms. All components are tied together in a number of dedicated compiler passes that perform the necessary analysis and synthesis steps for both hard- and software.
 |
| |
| Figure 22: Design-Flow with PaCIFIC |
PaCIFIC enables the automatic composition of a data path comprising IP cores and program parts which are scheduled for hardware execution (see
compiler for adaptive computing systems), as well as its use from a software description that also sources and sinks the data. A natural approach for plain software would consider the two IP cores to be C functions. From a sequence of such function calls, the hardware pipeline is automatically inferred. This requires additional information about the hardware "functions", e.g., the interface protocol or which registers must be programmed with certain values to execute a dedicated IP function. The IP developer deposits this information, which is formulated in the description language mentioned above, in a repository along with the IP core. Thus, the software developer does not have to be aware of the actual mechanisms involved in realizing the data path.
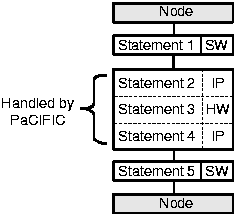
PaCIFIC enables COMRADE to integrate and access complex IP cores. To this end, additional compiler passes are inserted into COMRADE. These extra steps access the PaCIFIC descriptions to find idiomatic hardware function calls in the C source program. In the first pass, the internal intermediate representation of the C program is scanned for IP cores. In the remaining course, they are exempted from the existing C-to-hardware compilation passes. The intermediate representation node for the basic block holding the IP calls is thus split between software execution and synthesized hardware data paths on the one hand and IP core execution on the other hand. Afterwards the intermediate representation is searched for hardware pipelines. These are assembled both from the automatically compiled hardware data paths as well as from the IP calls which are adjacent in the control flow (see Figure 23).
 |
| |
| Figure 23: Pipeline of combined hardware nodes |
Platforms and System Composition
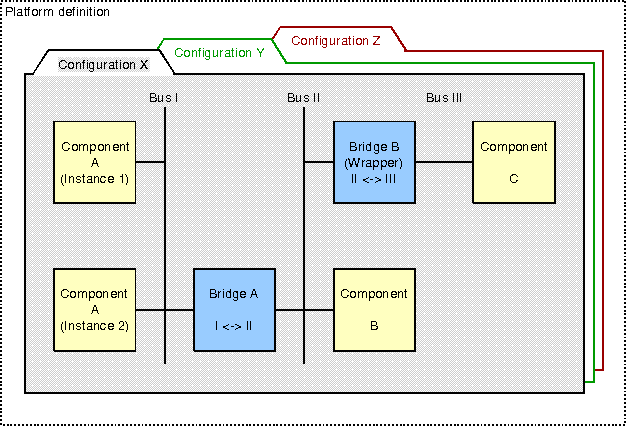
Platforms play an important role in the composition of entire from existing components. In this context, a platform represents a system environment, into which one or more hardware- or software components may be embedded. Since the design and use of platforms requires considerable expertise from a system implementor, we aim to automate this process. As the first step, our research deals with platform and component descriptions that are sufficiently complete to allow a tool flow to automatically compose a system fitting the user's requirements.
 |
| |
| Figure 24: Structure of a Platform Definition |
Platform configurations are the core part of a platform definition. A configuration consists primarily of component or bridge instantiation statements: A component instantiation binds a block with its full functionality to the platform. In contrast, the bridge instantiation expects a block which only provides address translation and data transfer between its interfaces. The platform is composed by connecting the interfaces of the instantiated blocks employing an interface binding mechanism which automatically composes designs by connecting interfaces with matching characteristics. The interface binding is a stepwise process which is started when the platform or design is composed for later use. It operates in a rule-based fashion, guided by user-imposed external constraints.
A General Introduction to Adaptive Computing Systems
While modern chip fabrication technology allows the packing of ever more transistors onto a single die, each fabrication run itself also grows increasingly complex (and correspondingly expensive). Thus, fewer design starts will actually be able to economically exploit the fabrication advances.
One way out of this dilemma is offered by highly programmable or configurable circuits. Here, a fixed-silicon platform can be customized after the fabrication for the application specific-requirements. Among the many advantages of this approach are the cost-reduction due to the economy-of-scale available when mass-producing the underlying platform, and the ability to nimbly react to requirements changing during the design process (no new fab run required). The latter is a common occurrence especially for products that have to follow standardization processes that have not arrived at final specifications themselves.
Conventional CPUs (including DSPs) exist on one end of the flexibility spectrum. Here, the entire application is defined purely in software, having the greatest degree of malleability.
Unfortunately, though, this approach can be inefficient: If only a small part of the application has high performance requirements (e.g., the IDCT step for DVD decoding), the processor has to be sufficiently powerful to handle these peak requirements, even if this processing capability remains unused for the rest of the program. In these situations, specialized hardware acceleration can be employed to great effect (e.g., dedicated IDCT circuits on graphics cards). By going this route, however, the limitations of fixed-function hardware come into play once again: The function of these specialized circuits cannot be altered after fabrication. While this might be acceptable for some limited-scope applications, it proves impractical for more complex scenarios that have to fit a wider area of requirements.
Programmable hardware accelerators are one attempt to solve this problem. One example includes current-generation graphics processors that allow the insertion of user-provided micro-code at various stages in the graphics pipeline. Even though the core operations are realized as dedicated hardware relying on architectures utterly different from that used in conventional CPUs, the programmability still ensures the flexibility required by programmers.
A larger degree of variability is offered by reconfigurable circuits. Here, even the hardware architecture can be customized after fabrication to fit the application. While this capability comes at the price of higher silicon area requirements and lower performance, the standardized nature of the devices makes them suitable for mass-production on a state-of-the-art process. In that case, the resulting higher density, speed, and economy-of-scale effects compensate for these disadvantages.
The spectrum of configurability ranges from once (for the entire lifetime of the application) over multiple times (several reconfigurations for the lifetime of the application) to dynamic (multiple reconfigurations during a single execution of the application). Anti-fuse based devices are generally used for the first scenario. In the second case, a device already installed can be upgraded after its delivery to the customer. Base technologies such as EEPROM- based chips are common here.
Adaptive Computing Systems (ACS) fall into the dynamic category. They modify hardware functions at run-time to accommodate the needs of the application. This can extend to even customize the hardware for different execution phases or modes of the same application. For example, the compression and decompression stages of an application might require different hardware architectures for optimal performance. In the extreme case, the hardware can be altered to fit the data specific to a single program execution. E.g., a crypto application might request hardware specific for a certain value of the encryption key.
A number of technologies can be used as the base for ACS. The most common one today employs FPGAs, which now have sufficient logic capacity to actually house compute applications. A more recent development are Network Processors. One of their major difference to FPGAs is the use of Multi-Bit-ALUs as primitives instead of the single-bit logic blocks generally employed on FPGAs. For many compute operations (which also process multi-bit words in general), the coarser granularity of Network Processors can result in less area overhead and faster reconfiguration times.
The theoretical performance potential of ACS can only be realized efficiently (in terms of programmer time) through the use of dedicated programming environments. High-level tools must be able to accept algorithms in a notation the user is familiar with (e.g., C, MATLAB, FORTRAN) instead of more exotic formats (and HDLs are considered exotic from the perspective of most software developers!). The tools must then be able to efficiently (now in terms of performance) map the algorithms described in this fashion to the target ACS. This is non-trivial, since the high-level languages offer few explicit constructs (parallelism, bit-widths, etc) that can assist the ACS compiler to arrive at fast hardware implementations.
Due to the software-like flexibility of the hardware (sometimes called soft-hardware or Agileware), soft- and hardware aspects of the final application have to be considered as a whole.
Design flows and
ACS architectures have to be carefully matched together: Hardware attributes influence the optimization algorithms used in the tools, while various optimization methods require specific support in the ACS hardware.
